Hoofdstuk 29 Single-case designs
- single-case designs.
- Onderzoekspracticum experimenteel onderzoek (PB0422)
29.1 Inleiding
In de psychologie wordt het single-case design (SCD), ook wel het N-of-1 design, gebruikt om verandering binnen een individu gedurende een bepaalde periode te bestuderen. Het design is meestal experimenteel, waarbij de persoon als zijn eigen controle fungeert. Er worden veel metingen gedaan (tijdreeks) bij één of een beperkt aantal deelnemers op één of meer variabelen. Op een bepaald moment wordt er een interventie of manipulatie geïntroduceerd, waarvan wordt aangenomen dat deze de metingen beïnvloedt. In feite gaat het hier om een speciaal geval van een herhaalde-metingen design.
Wanneer er geen experimentele manipulatie of interventie plaatsvindt, spreekt men meestal van case studies of longitudinale designs, die met tijdreeksanalyse-technieken worden geanalyseerd. Deze niet-experimentele designs worden veel toegepast in andere vakgebieden, zoals de economie.
De basis voor alle soorten SCD-analyses is het analyseren van veranderingen in de metingen ten opzichte van het begin van de interventie. De SCD-benadering is nuttig wanneer je verwacht dat de verandering binnen een individu afhankelijk is van kenmerken van het individu. In zo’n geval kan de groepsvergelijking, zoals bij klassieke experimenten, namelijk een vertekend beeld geven.
Ondanks de naam worden in een SCD vaak meerdere personen onderzocht. Toch is de naam SCD nog steeds van toepassing, omdat de grootste interesse ligt bij de veranderingen binnen een individu. SCD’s zijn onder andere heel waardevol in kleine populaties, wanneer er bijvoorbeeld sprake is van een lage prevalentie van het te bestuderen gedrag.
Designs met één persoon kunnen informatie leveren op drie kennisniveaus. Het eerste niveau is puur beschrijvend, namelijk het patroon van verandering binnen een individu. Via visualisatie van de data kan het veranderingsproces inzichtelijk worden weergeven en met relatief eenvoudige statistieken kan het veranderingsproces worden beschreven. Het tweede niveau is correlationeel van aard en beschrijft het (lineaire) verband tussen verschillende variabelen over de tijd om zo zicht te krijgen op de samenhang in de trajecten van voorspellers en uitkomstvariabelen. Het derde niveau is causaal van aard. Op dit niveau wordt gezocht naar antwoorden op vragen rondom de effectiviteit van een interventie, oftewel ‘had de interventie effect en hoe sterk was dit effect?’
29.2 AB-design en alternatieven
Het AB-design is het eenvoudigste single-case design, bestaande uit twee fasen. De eerste fase van opeenvolgende metingen (A) fungeert als de controleconditie en de tweede fase (B) als de (post-)interventieconditie. Het AB-design is breed toepasbaar en bootst de gangbare praktijk na, waarbij een aantal metingen van het te onderzoeken gedrag worden gedaan voor en na een interventie.
De interne validiteit van het AB-design is echter onvoldoende om causale conclusies (over het interventie-effectiviteit) te kunnen trekken. Het AB-design wordt daarom een pre-experimenteel design genoemd. Om alternatieve verklaringen te kunnen uitsluiten en dus wel te kunnen concluderen dat de gedragsverandering het gevolg is van de interventie, is omkeerbaarheid in het design belangrijk. Omkeerbaarheid houdt in dat het gedrag terugvalt naar het startniveau wanneer de interventie wordt gestopt, en dat de gedragsverandering weer zichtbaar is wanneer de interventie wordt hersteld. Dit kan bereikt worden met uitbreidingen op het AB-design, zoals het terugtrekkingsdesign (ABA-design) of het omkeringsdesign (ABAB-design).
Een alternatief om van het AB-design een experimenteel design te maken, is door het AB-design binnen proefpersonen te herhalen, bijvoorbeeld door meer dan één type gedrag te meten of door het gedrag in verschillende settings te meten. Een ander alternatief is om het AB-design bij meerdere deelnemers te repliceren, waarbij bij voorkeur de start van de interventie willekeurig wordt gevarieerd. Deze alternatieve designs zijn vooral handig wanneer omkeringsdesigns niet geschikt zijn vanwege niet-omkeerbaar gedrag, zoals bij het aanleren van vaardigheden of therapeutische verbeteringen.
Designs met meerdere AB-fasen genieten methodologisch de voorkeur, maar vaak is dit niet mogelijk in de psychologie, vanwege inhoudelijke of ethische redenen.
29.3 Effectgrootte
Elk onderzoek in herhaalde \(N=1\) studies levert bewijs voor de effectiviteit van een interventie. Hiervoor moeten één of meer effectgroottes worden berekend. Een effectgrootte beschrijft de sterkte van de associatie tussen variabelen en maakt het mogelijk om interventies in verschillende omstandigheden te vergelijken. Effectgroottes zijn ook belangrijk voor meta-analyses. Een mogelijk nadeel van effectgroottes is dat de interpretatie niet altijd duidelijk is.
Als betrouwbaarheidsintervallen voor een effectgrootte kunnen worden geconstrueerd, kan ook de onzekerheid rond de effectgrootte worden geschat, wat gezien kan worden als de belangrijkste kennis in statistische analyses. Een voorbeeld van een effectgrootte uit een AB-design is Cohen’s \(d\). Hierbij wordt het gemiddelde van de scores in de A-fase vergeleken met die uit de B-fase, gecorrigeerd voor de varianties in beide fasen.
29.4 Kwaliteitsrichtlijnen
In de afgelopen decennia hebben wetenschappers verschillende richtlijnen ontwikkeld om de kwaliteit van SCD-onderzoek te waarborgen. De Risk of Bias in N-of-1 Trials (RoBiNT)-schaal is voorgesteld als instrument om de methodologische kwaliteit van single-case designs te beoordelen. Deze schaal bevat \(15\) items die de kwaliteitsaspecten van SCD-onderzoek controleren. Voorbeelden van items zijn ‘Voldoet het design van het onderzoek aan de vereisten om experimentele controle aan te tonen?’ (item \(1\)) en ‘Was er een methode voor gegevensanalyse toegepast en werd er een reden gegeven voor het gebruik ervan?’ (item \(13\)). Daarnaast worden in de Single-Case Reporting guideline In BEhavioral Interventions (SCRIBE) richtlijnen gegeven voor de rapportage over SCD-onderzoek.
Het is van groot belang om deze kwaliteitsnormen te volgen, niet alleen om de validiteit van het onderzoek te waarborgen, maar ook om wetenschappelijke kennis te vergroten door het onderzoek toegankelijk te maken voor kritische beoordeling en replicatie.
29.5 Voorbeeld couple therapy data
In het volgende voorbeeld gebruiken we single-case data van acht personen over het functioneren binnen een relatie na een medische behandeling voor kanker. In dit voorbeeld richten we ons op de variabele responsiviteit (‘responsiveness’) naar de partner. Het onderzoek beslaat een relatief lange periode waarin met wisselende tussenpozen wordt gemeten. Fase A bestaat hier uit subfasen waarin diverse therapeutische gesprekken werden gevoerd. In fase B ligt de nadruk van de therapie op de partner’s responsiviteit.
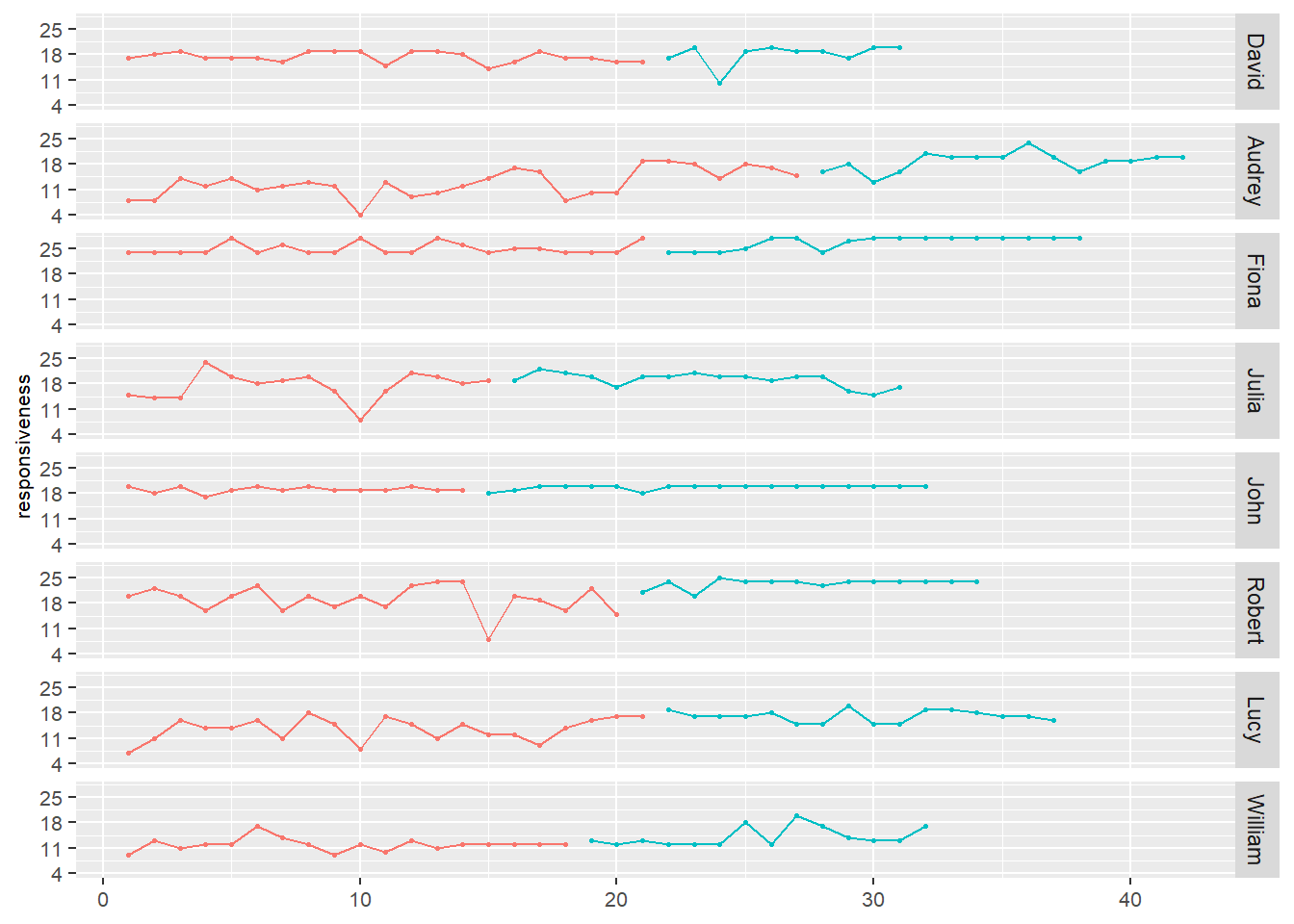
Figuur 29.1: Ruwe data van responsiviteit van acht deelnemers in twee fasen
Figuur 29.1 toont de ruwe data van de acht deelnemers, waarbij op de x-as het rangnummer van de metingen staat en op de y-as de mate van responsiviteit naar de partner. De kleuren geven aan in welke fase er is gemeten.
Als we naar de figuur kijken, lijkt er bij geen van de deelnemers een duidelijke trend te zien. Audrey lijkt de grootste vooruitgang te hebben geboekt. In Figuur 29.2 is het patroon van Audrey eruit gehaald en is de schaling van de y-as met responsiviteitsscores duidelijker weergegeven.
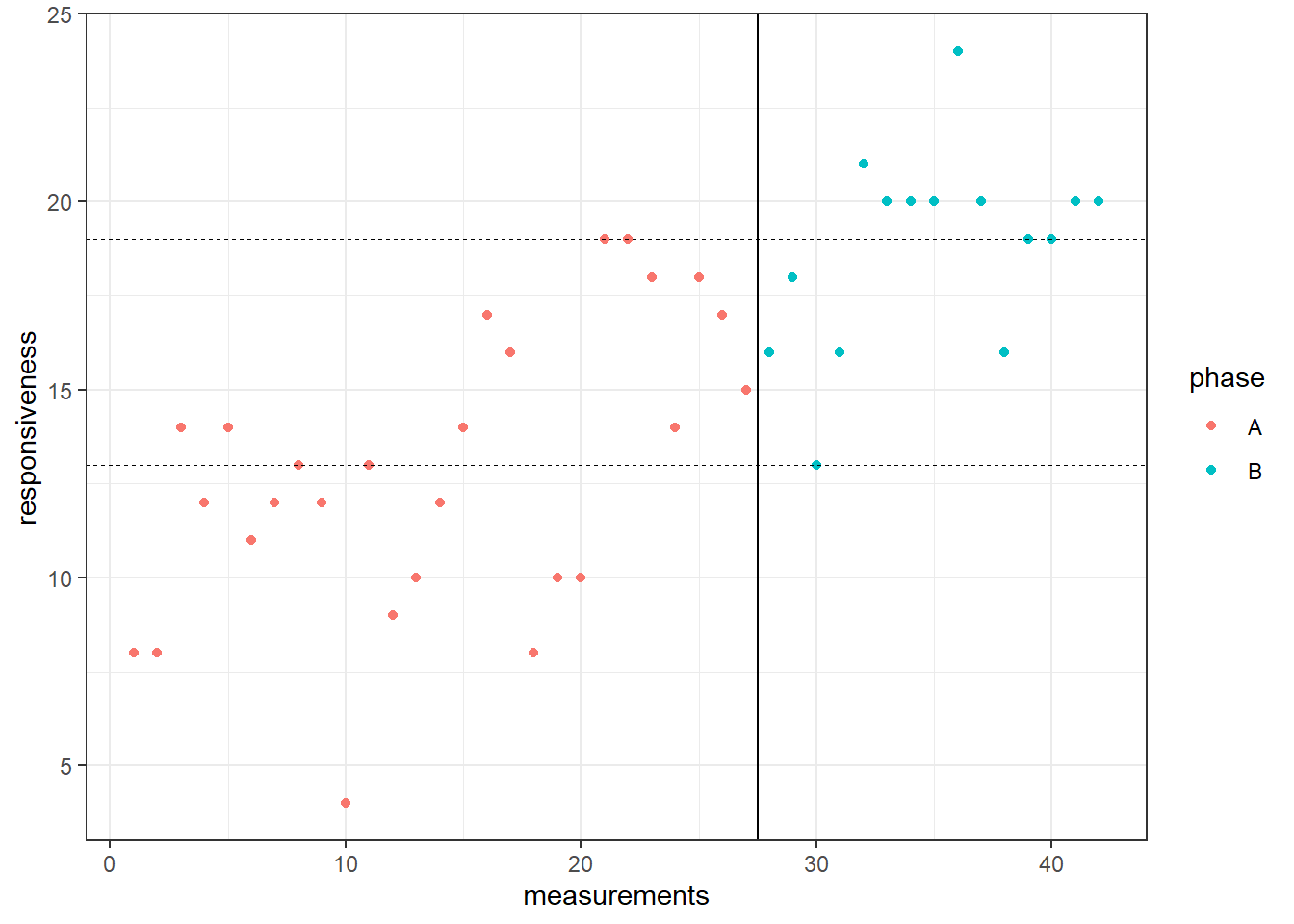
Figuur 29.2: Ruwe data van responsiviteit van Audrey
Het is belangrijk om bij de analyse van dit type data altijd te beginnen met een visuele inspectie van faseverschillen, trends en andere effecten. Daarnaast zijn er veel maten bedacht die nuttig kunnen zijn bij het kwantificeren van de effecten. We geven hier één voorbeeld.
Een eenvoudige maat is het percentage niet-overlappende gegevens (Engels: percentage of non-overlapping data, PND). De PND wordt gedefinieerd als het percentage metingen (scores) in fase B dat de hoogste score in fase A overschrijdt, wanneer de interventie tot doel heeft de scores te verhogen. Wanneer het verlagen van de scores het doel is, is PND het percentage scores in fase B onder de laagste score in fase A. Een hoge PND-waarde is een indicatie dat de interventie effectief is.
Voor Audrey is de PND = 0.53, wat betekent dat 53.3% van de scores van responsiviteit in fase B hoger ligt dan de hoogste score van fase A. In Figuur 29.2 zijn dit de groene punten boven de bovenste stippellijn, gedeeld door alle groene punten. Op basis hiervan zou een onderzoeker nu kunnen concluderen dat de interventie bij Audrey effectief is geweest, omdat enerzijds de visualisatie een duidelijke verbetering toont en anderzijds omdat 53.3% van de scores in fase B hoger is dan elke score uit fase A.
29.6 Randomisatietoets
Bij het interpreteren van de PND rijst de vraag in hoeverre dit resultaat toevallig is. Deze vraag is vergelijkbaar met het toetsen van de nulhypothese dat er in werkelijkheid geen effect is van de interventie en dat de gevonden verschillen toevallig zijn. Om dit te toetsen is de randomisatietoets ontwikkeld. Een randomisatietoets berekent in essentie (in dit voorbeeld) de PND voor alle mogelijke splitsingen tussen fasen A en B, gegeven de volgorde van de data. De resultaten worden vervolgens geordend en er wordt gekeken hoeveel procent van de PND-waarden groter zijn dan die van de oorspronkelijk gedefinieerde fase A en B.
Dit percentage is een maat voor de toevalligheid en kan worden beschouwd als een vorm van statistische significantie. Een lage waarde geeft aan dat de kans klein is dat de gevonden waarde berust op toeval. In zo’n geval kunnen we, net als in de klassieke statistiek, de nulhypothese verwerpen en aannemen dat de interventie een effect heeft gehad. Een hoge waarde betekent dat het voor het effect in deze data niet uitmaakt waar de scheiding tussen de beide fasen ligt. In dat geval is de interventie dus niet effectief geweest.
Via de randomisatietoets vinden we voor de PND-waarde van Audrey dat \(p=\) 0.63. Dit is een erg hoge waarde, wat aangeeft dat er bij veel andere splitsingen van de data in fase A en B PND-waarden gevonden worden die hoger of gelijk zijn aan de gevonden waarde bij de werkelijke splitsing. De nulhypothese kan dus niet worden verworpen en de conclusie dat de interventie effectief was, is mogelijk niet terecht.
Het principe achter de randomisatietoets is dus heel eenvoudig en maakt geen gebruik van allerlei aannames rondom de verdeling van de scores. De randomisatietoets kan worden toegepast bij heel veel maten. Een nadeel van deze toets is dat er een minimumwaarde bestaat, die wordt bepaald door het aantal datapunten. Bij bijvoorbeeld \(10\) datapunten kan de p-waarde nooit lager worden dan \(0.10\).