Hoofdstuk 30 Anova voor herhaalde-metingen
- ANOVA voor herhaalde-metingen
- herhaalde-metingen anova versus multilevel analyse
- aannames bij herhaalde-metingen.
- Onderzoekspractium experimenteel onderzoek (PB0422)
30.1 Inleiding
Bij een klassiek experiment wordt al snel gedacht in ‘groepen’, bijvoorbeeld een groep proefpersonen die in een experimentele conditie geplaatst wordt en die vergeleken wordt met een groep proefpersonen die in de controleconditie is ingedeeld. Maar soms kunnen de proefpersonen ook hun eigen controlegroep zijn. In herhaalde-metingen designs krijgen de proefpersonen alle experimentele (dus ook de controle-) condities aangeboden. Het is dan nog steeds mogelijk om proefpersonen in groepen te verdelen voor experimentele controle of manipulaties, maar de kern van het experimentele design zit in het aanbieden van alle experimentele manipulaties aan iedere proefpersoon.
Dit hoofdstuk bespreekt de situatie waarin een experimentele manipulatie niet (alleen) tussen personen maar ook binnen personen plaatvindt. Designs zoals in de hoofdstukken Factoriele-anova en Variantieanalyse zijn besproken betreffen zogenaamde between-subjects designs. Vergelijkingen worden tussen proefpersonen gemaakt, de proefpersonen worden daarbij willekeurig aan één van de elkaar uitsluitende condities toegedeeld. Bij herhaalde-metingen designs, of anders gezegd, bij de zogenaamde within-subjects designs worden personen aan meerdere experimentele condities blootgesteld, waarbij de afhankelijke variabele meerdere keren wordt gemeten. Omdat dit niet tegelijkertijd kan, vindt de blootstelling aan de condities en metingen na elkaar plaats, vandaar de naam herhaalde-metingen (Engels: repeated measures, RM). Het is dus niet zo dat herhaalde-metingen altijd betekent dat er eenzelfde ‘iets’ herhaaldelijk gedaan of gemeten wordt, zoals in een longitudinaal design. Een longitudinaal design is een specifiek type within-subject design, maar herhaalde-metingen kunnen dus ook gaan over verschillende condities die een proefpersoon doorloopt. De within-subjects and between-subjects designs kunnen ook worden gecombineerd: dit worden dan “mixed designs” genoemd.
30.2 Herhaalde-metingendesign
In hoofdstuk over Variantieanalyse is de oneway anova besproken, een design met één numerieke afhankelijke variabele en één nominale predictor variabele. In hoofdstuk over factoriele-anova bestond het design uit één numerieke afhankelijke variabele en twee of meer nominale predictor variabelen. In dit hoofdstuk bestaat het design uit twee of meer afhankelijke variabelen en zijn (nominale) predictor variabelen geen vereiste. Er zijn in principe meerdere afhankelijke variabelen, maar meestal wordt dezelfde afhankelijke variabele meerdere keren gemeten.
Een herhaalde meting betekent niet automatisch dat er sprake is van ‘chronologie’. Simpel gezegd: er hoeft niet altijd ‘over tijd’ iets herhaald te worden. Een voormeting-nameting-followup is een klassiek soort herhaalde-metingen design, maar een opzet waarin alle proefpersonen alle (experimentele) condities doorlopen kan ook een herhaalde meting zijn. Bijvoorbeeld, wanneer proefpersonen op de computer de neutrale controlestimuli krijgen (zoals landschapsplaatjes) afgewisseld met negatieve-affectstimuli (verontrustende plaatjes), en positieve affectstimuli (leuke plaatjes). In dit geval zijn alle drie condities (neutral, negatief, positief) door alle proefpersonen doorlopen, waarbij de volgorde in principe willekeurig is. Zie herhaalde-metingen dus als een situatie met ‘meerdere afhankelijke variabelen’ of als de verschillende categorieën van een afhankelijke variabele.
Het voordeel van een within subjects designs is dat allerlei storende invloeden die verschillen tussen personen veroorzaken, onder controle worden gehouden. Eventuele storende variabelen zoals leeftijd, een persoonlijkheidskenmerk of intelligentie zijn per definitie constant binnen een persoon en worden in een within subjects design dus onder controle gehouden, terwijl deze variabelen in between subjects designs alleen via randomisatie onder controle kunnen worden gehouden.
Daarentegen is een beperking van within subjects designs dat bij veel onderzoeksvragen niet alle manipulaties herhaaldelijk bij dezelfde subjecten kunnen worden toegepast. Een voorbeeld is een interventie met verschillende psychotherapietherapievormen. Het is weliswaar mogelijk om de therapievorm na een aantal weken te wijzigen, maar het is waarschijnlijk dat de eerste therapie nog doorwerkt, zodat het heel lastig is het effect van verschillende therapievormen te onderscheiden. Daarvoor zou een factorieel design meer geschikt zijn. Dat is een between subjects design en dan gaat het dus om verschillen tussen groepen personen. Met een herhaalde-metingendesign wordt een fundamenteel andere vraag beantwoord, namelijk welke verschillen er optreden binnen personen.
30.3 Volgorde-effecten en counterbalancing
Een risico in herhaalde-metingen designs is dat de interne validiteit bedreigd kan worden doordat erg op elkaar lijkende experimentele observaties zich herhalen. Het kan gebeuren dat er een leereffect ontstaat, en dat bijvoorbeeld een waargenomen toe- of afname over tijd of over condities het gevolg is van bekendheid met de test. Als in een experiment een proefpersoon eerst een nieuwsbericht moet lezen wat positieve emoties moet oproepen dan kan de proefpersoon bij een volgend nieuwsbericht wat negatieve emoties moet oproepen nog een effect (‘besmetting’) ervaren van de eerder opgeroepen positieve emoties.
Ook kan het zijn dat als na het eerste nieuwsbericht vragen gesteld werden, de proefpersoon bij het tweede nieuwsbericht al zo’n beetje weet wat er gevraagd gaat worden, en met die voorkennis het bericht anders leest. Denk ook aan experimenten waarin de prestatie van proefpersonen op een taak wordt gemeten. Ze kunnen dan per conditie opnieuw oefenen met de taak en worden er vanzelf beter in gedurende het experiment. Ook kan bij herhaalde metingen vermoeidheid optreden. Bijvoorbeeld: experimenten waarin reactiesnelheid geobserveerd wordt, kunnen lijden onder verslappende aandacht naarmate het experiment voortduurt.
De interne validiteit wordt dus bedreigd als alle proefpersonen dezelfde leer- of volgorde-effecten delen. Om deze reden is het vaak goed om zogeheten counterbalancing toe te passen. Counterbalancing betekent dat de experimentele condities in verschillende volgorden worden aangeboden. Er zijn vele manieren om te counterbalancen. Het is bijvoorbeeld mogelijk om de proefpersonen in twee groepen te verdelen. Groep A krijgt bijvoorbeeld eerst de controle- en daarna de experimentele conditie. Groep B krijgt als counterbalancing eerst de experimentele conditie aangeboden en dan pas de controleconditie. Deze vorm van counterbalancing wordt dikwijls ook een crossover study genoemd. Het is ook mogelijk om volledig willekeurig, per proefpersoon, de volgorde van experimentele condities toe te wijzen. Iedere methode heeft eigen voor- en nadelen, maar over het algemeen is er geen voorkeur voor hoe counterbalancing plaatsvindt.
De analyse van counterbalanced herhaalde-metingendesigns begint meestal met het toetsen of er volgorde effecten waren. Dikwijls start de analyse dan als een mixed-design ANOVA, dus een analyse waar ‘volgorde’ als een between-subjectvariabele aan de analyse is toegevoegd. Als dan blijkt dat volgorde geen factor van belang was, dan wordt meestal besloten om volgorde als factor uit de analyse te verwijderen. Indien volgorde wel invloed blijkt te hebben op de resultaten, dan wordt de factor (en eventuele interacties met volgorde) in het model gehouden. In de discussiesectie van een onderzoeksrapport wordt vervolgens gereflecteerd op hoe volgorde-effecten de interne validiteit van het design bedreigd hebben, en wat dit betekent voor de conclusies op basis van de resultaten.
30.4 De logica achter een herhaalde-metingen ANOVA
Net als alle andere ANOVA’s werkt een herhaalde-metingen ANOVA door het opdelen van soorten meetfout (error). Het grote voordeel van herhaalde-metingen ANOVA’s is dat ze individuele verschillen goed uit de meetfout kunnen trekken.
De F-waarde is een verhouding tussen signaal en ruis (zie bijvoorbeeld #ANOVA). De verhouding wordt in een between subject design over het algemeen uitgedrukt als:
\[\begin{equation} F = \frac{\text{variantie van de groepsgemiddelden}}{\text{gemiddelde van de varianties binnen groepen}} \tag{30.1} \end{equation}\]
Wat beknopter geschreven wordt als:
\[\begin{equation} \frac{MS_b}{MS_w} \tag{30.2} \end{equation}\]
De opdeling van de totale meetfout (SS_total) reflecteert het bovenstaande idee dat individuele scores een combinatie zijn van een groepsgemiddelde plus willekeurige ruis. Dus:
\[\begin{equation} SS_{Totaal} = SS_{Between} + SS_{Error} \tag{30.3} \end{equation}\]
In een puur herhaalde-metingendesign zijn geen variabelen opgenomen die als between-subjectfactors dienst doen. Maar je kan de herhaalde meting (de within-subjectfactor) op twee manieren bekijken. Enerzijds is er een verschil binnen proefpersonen. Het gemiddelde individuele verschil tussen condities kan dus vergeleken worden, net als bij een gepaarde t-toets. Anderzijds kunnen ook de gemiddelden per conditie met elkaar vergeleken worden, alsof het verschillende groepen zijn. In een herhaalde-metingen-ANOVA wordt de meetfout opgeknipt in een ‘individuele verschillen’-deel (within-subjects) en een ‘gemiddeld verschil’-deel (between subjects), en uiteindelijk in een residuele meetfoutdeel (error).
\[\begin{equation} SS_{Totaal} = SS_{Between (condities)} + SS_{Within (individuen)} + SS_{Error} \tag{30.4} \end{equation}\]
Het voordeel van het opdelen van de meetfout in enerzijds het verschil tussen gemiddelden van condities (between), en anderzijds vergelijkingen van individuele verschilscores tussen condities (within) is dat er minder residuele meetfout zal zijn. De F-waarde zal dan een deling zijn tussen een mate van variabiliteit boven de deelstreep en minder residuele meetfout onder de deelstreep. De F-waarde zal daarom hoger zijn dan wanneer de herhaalde meting niet zou zijn meegenomen, zoals bij between subjects designs. Een herhaalde-metingendesign levert dus een sterker signaal op dan een design zonder herhaling.
Op deze manier kan voor elke factor (within of between subjects) een F-waarde worden berekend, evenals van de interactie tussen de factoren. Net als bij andere designs kan vervolgens worden getoetst of de F-waarde met de bijbehorende vrijheidsgraden significant is.
Hier zit echter wel een ‘maar’ aan. Een herhaalde-metingendesign kan een lagere F-waarde opleveren als de scores in verschillende condities gemiddeld genomen erg op elkaar lijken, zelfs als individuen tussen condities wel duidelijk verschil laten zien. Dit heeft te maken met het verlies van vrijheidsgraden in een ANOVA-design met herhaalde metingen. Het verschil tussen condities moet dus voldoende groot zijn om het verlies van vrijheidsgraden te compenseren.
30.5 Herhaalde-metingen en het lineair model
In dit boek hebben we de diverse variantie-analysemodellen benaderd met een lineair model. Ook bij ANOVA voor herhaalde metingen kunnen we het lineair model gebruiken. Er doet zich hier echter een complicatie voor, omdat er meerdere metingen zijn van iedere persoon (subject). Bij een ‘gewoon’ lineair model is de aanname dat de metingen onafhankelijk zijn van elkaar. De metingen bij een herhaalde-metingen-ANOVA zijn echter afhankelijk van elkaar, omdat de afhankelijke variabele meerdere keren gemeten wordt bij elke persoon. In het lineair model kunnen we dat als volgt weergeven:
\[\begin{equation} Y_{ik} = b_{0i} + b_{1i}X_{ik} + \epsilon \tag{30.5} \end{equation}\]
We zien hier een model waarbij de afhankelijke variabele (\(Y\)) twee indices (\(i\) en \(k\)) heeft, waarbij \(i\) de gebruikelijke index is van de personen (\(i = 1, ... , n\)), die soms wordt weggelaten om de notatie simpel te houden, en \(k\) het aantal herhaalde-metingen aangeeft, bijvoorbeeld (\(k = 1,2,3,4\)) als er \(4\) herhaalde-metingen zijn. Bij iedere persoon is dan dus vier keer de afhankelijke variabele gemeten of geobserveerd. De variabele \(X\) geeft de manipulatie aan, waarbij de index \(k\) aangeeft om welke manipulatie (bv. \(1\) = oranje pil, \(2\) = gele pil, etc) of om welk meetmoment (bv. \(1\) = voormeting, \(2\) = nameting, \(3\) = follow-up na \(3\) maanden, \(4\) = follow-up na \(6\) maanden) het gaat. In dit soort lineaire modellen wordt vaak aangenomen dat iedere persoon zijn eigen intercept \(b_{0i}\) en eigen effect van de manipulatie \(b_{1i}\) heeft. Dat is de reden dat de index \(i\) erbij staat.
De boodschap is dat ook voor een herhaalde-metingen anova het lineair model kan worden gebruikt, maar dat er een andere analysetechniek dan lineaire regressieanalyse nodig is vanwege de afhankelijkheid in de data. Deze andere techniek wordt multilevel analyse genoemd, omdat in de data meerdere geneste niveaus aanwezig zijn (bijvoorbeeld meetmomenten binnen personen). In het hoofdstuk over multilevel analyse zal hier verder op worden ingegaan. In dit hoofdstuk laten we ook de klassieke herhaalde metingen ANOVA (meestal afgekort als RM-ANOVA) zien.
30.6 Multilevelanalyse versus RM-anova
De klassieke benadering voor de analyse van herhaaldelijke metingen anova wordt aangeduid met RM-anova. Dit type analyse komt neer op een eenvoudig lineair model, waarbij aan verschillende extra aannames moet worden voldaan. Het voordeel van de RM-anova benadering boven de multilevel aanpak is dat het eenvoudiger is en dat veel in de literatuur beschreven analyses van dit type designs zijn gebaseerd op RM-anova analyses. Het is daarom goed om enige kennis te hebben van RM-anova. Maar bedenk dat het schenden van de veronderstellingen van RM-anova problematisch kan zijn. Hieronder bespreken we de belangrijkste verschillen tussen RM-anova en de multilevel analyse (MLA) aanpak. Daarna gaan we dieper in op de aannames bij RM-anova.
30.6.1 MLA doet minder strikte aannames.
MLA is een hele brede techniek die ook buiten de context van ANOVA kan worden gebruikt. MLA veronderstelt geen constante varianties (homogeniteit van de varianties of homoscedasticiteit), constante covarianties (compound symmetry) of constante varianties van de verschilscores (sphericity). Met andere woorden, in tegenstelling tot RM-ANOVA, zijn deze aannames voor MLA niet noodzakelijk.
30.6.2 MLA maakt een hiërarchische structuur mogelijk.
MLA kan worden gebruikt voor steekproefprocedures van een hogere orde (bijvoorbeeld, personen, die worden gemeten op verschillende dagen en diverse keren binnen een dag), terwijl RM-anova zich beperkt tot het onderzoeken van steekproefprocedures op twee niveaus (bijvoorbeeld personen, gemeten op verschillende tijdstippen).
30.6.3 MLA kan ontbrekende gegevens verwerken.
Ontbrekende gegevens zijn toegestaan in MLA zonder extra complicaties te veroorzaken. Met RM-ANOVA daarentegen moet de hele meetreeks worden uitgesloten voor proefpersonen waarvan ook maar één datapunt ontbreekt. Ontbrekende gegevens en pogingen om met ontbrekende gegevens om te gaan (bijvoorbeeld door de ontbrekende gegevens te ‘imputeren’ op basis van het gemiddelde van de niet-ontbrekende gegevens van de persoon), kunnen namelijk voor problemen zorgen met RM-ANOVA.
30.6.4 MLA kan rekening houden met variatie in meetmomenten
MLA kan ook gegevens verwerken waarin er variatie is in de exacte timing van de gegevensverzameling. Bijvoorbeeld: als de tijd tussen twee herhaalde metingen niet altijd hetzelfde is. Een longitudinale studie kan bijvoorbeeld proberen metingen te verzamelen op de leeftijd van 6 maanden, 9 maanden, 12 maanden en 15 maanden. Deelnemersbeschikbaarheid, feestdagen en andere planningsproblemen kunnen echter leiden tot variatie in de momenten waarop gegevens feitelijk worden verzameld. Deze variabiliteit kan in MLA worden meegenomen in het voorspelmodel. In tegenstelling tot RM-ANOVA is het in MLA ook niet noodzakelijk dat de intervallen tussen de meetpunten voor elke proefpersoon gelijk zijn.
30.6.5 MLA kan omgaan met verschillende meetniveaus
Zowel RM-ANOVA als MLA veronderstelt dat de afhankelijke variabele continu is, wordt gemeten op een interval- of ratioschaal en dat de residuen normaal verdeeld zijn. Er zijn ook gegeneraliseerde lineaire modellen voor andere typen afhankelijke variabelen, zoals categorische, ordinale, discrete tellingen, maar ANOVA is dan geen optie. Er is dus geen RM-ANOVA-equivalent voor ‘count’- of logistische regressiemodellen. MLA kan wel met dit soort data omgaan.
30.6.6 MLA kan omgaan met niet-gebalanceerde onderzoeksopzetten
In tegenstelling tot MLA werkt RM-anova niet goed wanneer de onderzoeksopzet niet gebalanceerd is, een situatie die in de praktijk zeer vaak voorkomt. Gebalanceerd houdt in dat er (ongeveer) evenveel mensen in alle condities zitten. In een ongebalanceerd experimenteel ontwerp bevatten een of meer condities dus meer of juist minder deelnemers.
Conclusie
Als het ontwerp heel eenvoudig is en er zijn geen ontbrekende gegevens, dan leveren RM-anova en een MLA waarschijnlijk identieke resultaten op. Bijvoorbeeld, een pre-post ontwerp (met slechts twee herhalingen) of een experiment met een enkele ‘between-subjects’-factor en een enkele ‘within-subjects’-factor. Als dat het geval is, is RM-anova meestal prima. De flexibiliteit van MLA-modellen wordt belangrijker naarmate het onderzoeksontwerp gecompliceerder in elkaar steekt of wanneer er (veel) ontbrekende waarden zijn.
30.7 Assumpties van een RM-anova
Een RM-anova is een lid van de anova-familie en deelt daarom alle assumpties die gemeenschappelijk zijn aan alle anova’s, zoals de normaliteit van residuen (zie het hoofdstuk over anova). Maar een RM-anova schendt by design een belangrijke assumptie van anova’s, namelijk de onafhankelijkheid van de residuen. Omdat in herhaalde-metingen anova’s observaties herhaaldelijk zijn gedaan bij dezelfde proefpersonen zal de meetfout van een proefpersoon op taak A deels ook optreden in taak B. Binnen proefpersonen is een deel van de meetfout gecorreleerd over taken heen.
30.7.1 Onafhankelijkheid van residuen tussen proefpersonen
In het geval van RM-anova’s wordt de assumptie gedaan dat de meetfout tussen proefpersonen willekeurig (random) is.
30.7.2 Sphericiteit
Een unieke assumptie van een RM-anova is de assumptie van sphericiteit (uitgedrukt als \(\varepsilon\)). Deze assumptie lijkt conceptueel wel heel sterk op de assumptie van homogeniteit van varianties, ook wel homoscedasticiteit genoemd. Bij homoscedasticiteit was het idee dat vergeleken groepen enkel verschilden in gemiddelde, maar hetzelfde patroon van spreiding vertoonde, dus gelijke varianties hadden. Bij herhaalde-metingen wordt eigenlijk hetzelfde verwacht, dus dat herhaalde-metingen dezelfde varianties hebben. Maar omdat herhaalde-metingen geen onafhankelijke metingen zijn zit er een wiskundig addertje onder het gras.
Herhaalde metingen hebben een ingebakken verband met elkaar omdat ze uit dezelfde bron afkomstig zijn (bijvoorbeeld van dezelfde proefpersoon). De herhaalde metingen zijn dus altijd een beetje met elkaar gecorreleerd. Dat is voor RM-ANOVA niet erg, zolang we kunnen aannemen dat die afhankelijkheid constant is. Dat is de assumptie van sphericiteit. Specifieker is het de assumptie dat de variantie tussen herhaalde metingen vergelijkbaar is en dat er niet twee condities zijn die meer van elkaar afhankelijk zijn dan twee andere. Nog concreter: het betreft de aanname dat de verschilscores van variantieparen gelijk zijn. Dit lichten we hieronder toe met een simpel rekenvoorbeeld.
In onderstaande tabel worden drie herhaalde metingen getoond, ieder met een aantal deelnemers met op elke herhaalde meting een score. Om de sphericiteit te berekenen wordt eerst per paar van herhaalde metingen een verschilscore berekend. Van die verschilscores worden varianties berekend, en de varianties worden vervolgens naast elkaar gelegd om te evalueren of ze gelijk zijn.
| Conditie_A | Conditie_B | Conditie_C | A_minus_B | A_minus_C | B_minus_C |
|---|---|---|---|---|---|
| 8 | 10 | 6 | -2.0 | 2 | 4 |
| 7 | 7 | 4 | 0.0 | 3 | 3 |
| 6 | 2 | 5 | 4.0 | 1 | -3 |
| Variantie: | 9.3 | 1 | 14 |
In de tabel is te zien dat er bij drie condities {A, B, C} drie paren te vergelijken zijn, namelijk {A-B}, {A-C} en {B-C}. In het voorbeeld zijn er drie erg verschillende varianties voor de verschilscores, namelijk \(9.33\) voor verschilscore A-B, een beduidend lagere variantie van 1.00 voor verschilscore A-C, en de hoogste verschilscore van \(14.33\) voor verschilscore B-C. Merk op dat het onmogelijk is om verschilscoreparen te vergelijken als er maar twee herhaalde metingen zijn. Als er maar twee binnenproefpersonencondities zijn, zoals A en B, of een voor- en nameting, dan is er maar één paar te vormen om een verschilscore op te berekenen, bijvoorbeeld A-B. Om deze reden is sphericiteit niet gedefinieerd in herhaalde-metingendesigns met slechts twee herhaalde metingen.
Het is niet de bedoeling om zo op het oog te bepalen of varianties van verschilscores verschillen. De assumptie van de sphericiteit wordt in de meeste analysesoftware getoetst met Mauchly’s test of sphericity.
Wanneer de assumptie van sphericiteit geschonden wordt, bijvoorbeeld omdat de \(p\)-waarde van de sphericiteits-statistiek significant is (\(p < .05\)), dan moet er voor de schending van deze assumptie gecontroleerd worden. Dit wordt dikwijls gedaan door eerst te kijken naar de ernst van de afwijking. Een toets van sphericiteit drukt de sphericiteit in een epsilon (\(\varepsilon\)) uit. Als de epsilon nog tamelijk hoog is, dus \(\varepsilon > 0.75\), dan wordt de schending van de assumptie nog als mild beschouwd. Een kleine correctie op de vrijheidsgraden wordt dan als voldoende geacht om de assumptieschending mee te ondervangen. In de regel betekent dit dat er dan gekozen wordt voor een Huyn-Feldt F-waarde, dus een F-toets waar een milde correctie op de df heeft plaatsgevonden. Als de epsilon vrij laag wordt beschouwd, dus \(\varepsilon < 0.75\), dan wordt in de regel de zwaardere Greenhouse-Geisser correctie gekozen.
Om het voorbeeld in de tabel af te ronden: Als de data in de tabel getoetst zou worden met een Mauchly’s test of sphericity, dan zou hieruit komen dat Mauchly’s W(2) = \(0.105\), \(p = .324\), \(\varepsilon_{Huyn-Feldt}\) = \(0.618\). De test is niet significant, dus we zouden kunnen stellen dat sphericiteit aangenomen mag worden. Maar de steekproef is maar drie observaties groot, dus het is waarschijnlijk dat de best lage \(\varepsilon\) van \(0.618\), wat op een forse afwijking van sphericiteit duidt, op basis van de lage steekproefgrootte niet-significant is. De les is hier waarschijnlijk om geen herhaalde-metingen analyse te doen op slechts drie proefpersonen.
30.7.2.1 Korte samenvatting van de aanname van sphericiteit
Als het resultaat van Mauchly’s test significant is, kijk dan in de output naar de \(\varepsilon\): Als Huyn-Feldt \(\varepsilon > 0.75\), gebruik dan de Huyn-Feldt correctie Als Greenhouse-Geisser \(\varepsilon < 0.75\), gebruik dan de Greenhouse-Geisser. Simpel ezelsbrugje: Als \(\varepsilon\) kleiner is dan \(0.75\), dan is er Grof-Geschut nodig, dus Greenhouse-Geisser.
30.7.3 Normaliteit van de residuen
Ook de normaliteit van de residuen is net anders dan in de (univariate) ANOVA’s zoals behandeld in het hoofdstuk Variantieanalyse. In een within subject design zijn er meerdere afhankelijke variabelen, namelijk de obervaties per taak of meetmoment, die ieder in een eigen variabele gescoord zijn. Een herhaalde-metingendesign gebruikt deze afhankelijke variabelen als aparte ‘groepen’ die vergeleken worden. De residuen van de afhankelijke variabelen moeten dan wel normaal verdeeld zijn. Dit noemen we de assumptie van multivariate normaliteit. Die geldt voor alle multivariate modellen, dus modellen met meerdere afhankelijke variabelen.
30.8 Voorbeeld data
In het hoofdstuk over oneway-ANOVA (hoofdstuk Variantieanalyse), werden slaapkwaliteitdata gebruikt als voorbeeld. De afhankelijke variabele was hier de gerapporteerde slaapkwaliteit en er was één predictor, ‘activiteit’, die bestond uit drie condities: lezen, sporten, controle (geen instructie). In het hoofdstuk over factoriële ANOVA werd een tweede factor geïntroduceerd: ‘drinks’. Deze factor bestond uit twee categoriëen (condities): koffie en water. De subjecten werden willekeurig toebedeeld aan één van deze condities, waarbij men of de hele avond een hoeveelheid koffie moest drinken, of enkel water. In dit hoofdstuk over herhaalde-metingen-ANOVA gebruiken we dezelfde data, maar nu nemen we de variabele ‘drinks’ niet op als between-subjectsmanipulatie, maar als een within-subjectsfactor.
De variabele “activiteit” negeren we voor dit moment. Een deel van de personen dronk een week lang s’avonds alleen water, daarna een week lang koffie, en tenslotte een week lang een paar glazen alcohol (een extra conditie in de variabele ‘drinks’). Na iedere week rapporteerden de respondenten hun slaapkwaliteit van de afgelopen week. Iedere persoon heeft dus drie scores op slaapkwaliteit, elke score behoort bij een bepaalde manipulatie (hier: wat men heeft gedronken de week voorafgaand aan het rapporteren). Om mogelijke volgorde-effecten van de drank op te sporen zijn de deelnemers willekeurig aan twee mogelijke volgordes toebedeeld. Sommige deelnemers dronken de eerste week koffie, daarna een week water en daarna een week alcohol (c-w-a), en de andere groep deelnemers begon met een week alcohol, daarna water en tenslotte koffie (a-w-c). De variabele “volgorde” kan gezien worden als een between-subjects factor met twee categorieen.
In de volgende figuur zijn de data van 12 deelnemers getoond: de lijnen verbinden de datapunten van dezelfde deelnemer. De drie metingen zijn gelabeld met de interventie conditie die vooraf ging aan de desbetreffende meting (horizontale as).
De trend van de interventies is duidelijk te zien: in de week water drinken is de gerapporteerde slaapkwaliteit het hoogst, bij koffie meestal het laagst.
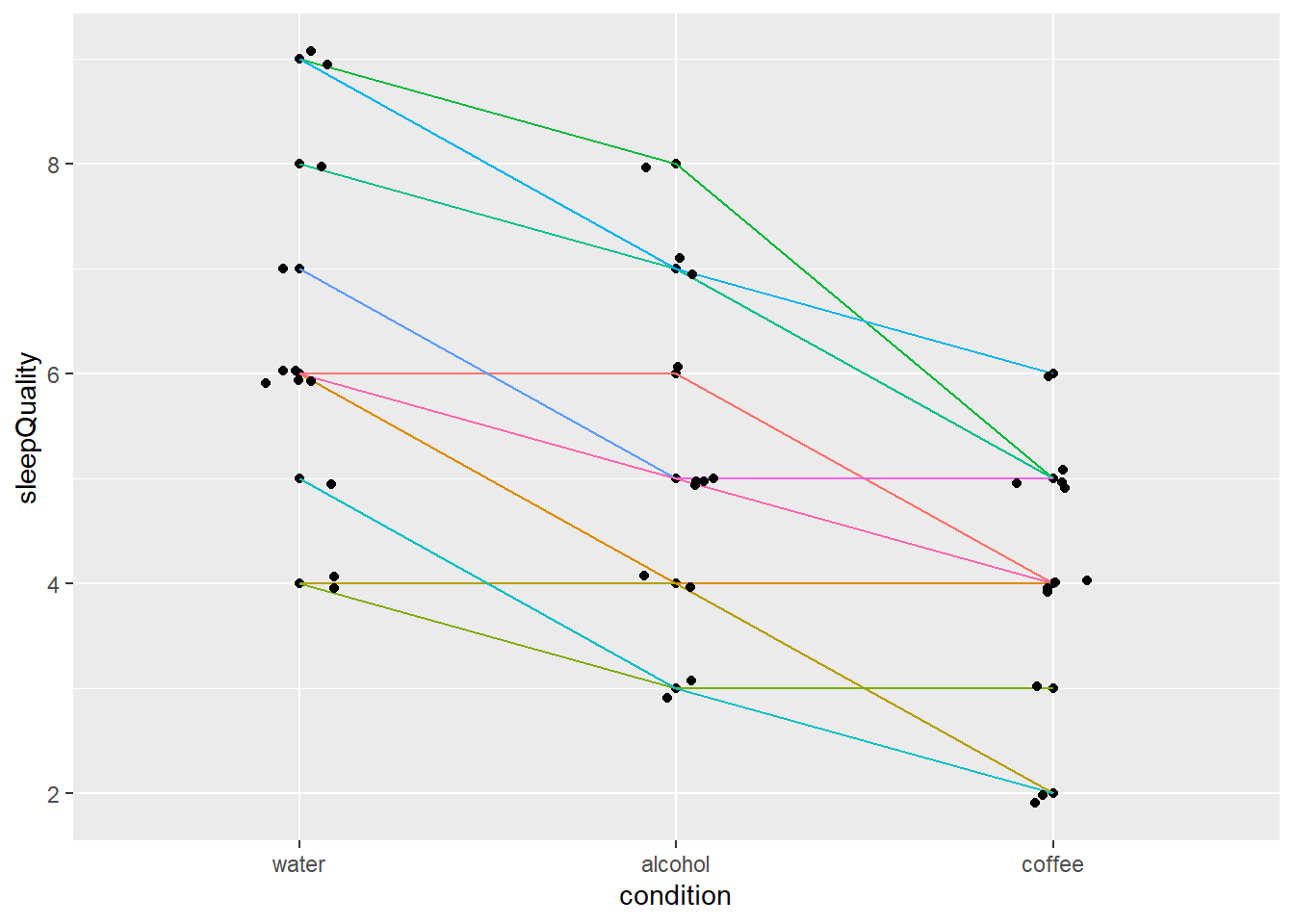
Figuur 30.1: Voorbeeld herhaalde-metingen.
Als we de data van dezelfde personen nogmaals plotten, maar nu gekleurd naar de twee volgordes waarin men de dranken heeft gedronken, zien we dat de volgorde geen systematisch effect lijkt te hebben op de slaapkwaliteit.
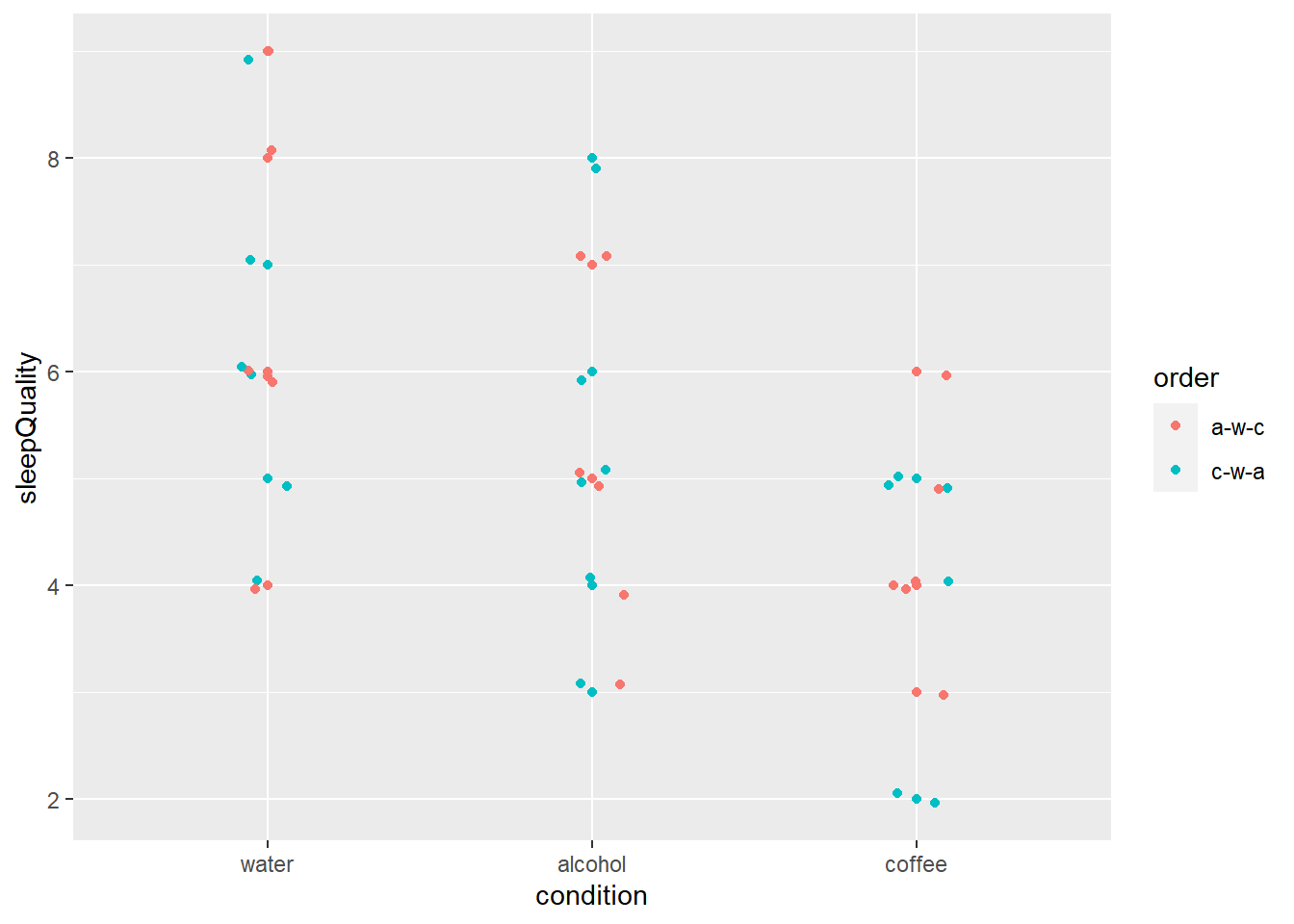
Figuur 30.2: Voorbeeld herhaalde-metingen, gekleurd naar volgorde.
30.8.1 Data in wide format versus long format
Bij herhaalde-metingendesigns staan de herhaalde metingen traditioneel als aparte variabelen in het databestand. Iedere rij correspondeert met een subject en elk subject heeft maar één rij met data. De afhankelijke variabelen worden bijvoorbeeld genoemd: slaapkwaliteit_1, slaapkwaliteit_2, slaapkwaliteit_3, waarbij meteen duidelijk wordt dat hetzelfde construct drie keer is gemeten. Dit format om de data te structureren, wordt aangeduid met de term ‘wide format’. Een wide format is nodig om de data te analyseren met een klassieke RM-ANOVA.
Wanneer je echter kiest voor de MLA-aanpak dan moeten de data in een zogenaamd ‘long format’ worden geplaatst. Elke score op de afhankelijke variabele komt dan in een aparte rij in het bestand: de scores van een subject staan dan onder elkaar in plaats van naast elkaar. Bij drie metingen van de afhankelijke variabele wordt het (long) bestand dus \(3\) maal zo lang, maar is er nog maar één afhankelijke variabele. Elk subject heeft in dat geval drie rijen in het bestand. Alle subjectspecifieke gegevens, zoals geslacht en leeftijd worden simpelweg gekopieerd, want deze blijven gelijk in de rijen die bij een bepaald subject horen. Er komt een nieuwe variabele bij die aangeeft om welke meting het gaat, zoals bijvoorbeeld een variabele ‘Meetmoment’, die de waarde \(1\) tot en met \(4\) heeft als er vier meetmomenten zijn.
Het voordeel van data in long format met één afhankelijke variabele is dat deze eenvoudiger te analyseren zijn met regressie-analyse-achtige technieken, zoals MLA. Wel moet rekening worden gehouden met de geneste structuur van dit soort data: metingen van dezelfde persoon zijn niet meer onafhankelijk van elkaar. Multilevel analysetechnieken zijn speciaal geschikt om dit soort geneste data te analyseren.
30.9 Mixed designs
We spreken van mixed designs als er zowel een between-subjectsfactor aanwezig is, als een within-subjectsfactor (herhaalde meting). Het voorbeeld van het slaapkwaliteitexperiment zouden we nog kunnen uitbreiden met de variabele ‘activiteit’ als een between-subjectsfactor zoals besproken in hoofdstuk Variantieanalyse. We krijgen dan een mixed design: de subjecten worden willekeurig aan een van de experimentele condities (sporten, lezen of controle) van de factor ‘activiteit’ toebedeeld en moeten daarnaast een bepaalde drank tot zich nemen, afhankelijk van de week. Aan het einde van het experiment heeft elke proefpersoon in één van de condities van de (between-subjects)factor ‘activiteit’ gezeten, maar hebben ze alle condities van de within-subjectsfactor ‘drank’ meegemaakt.
De eerder genoemde variabele ‘volgorde’ is een ander voorbeeld van een between-subjectsfactor, want iedere persoon valt in één van de twee categorieën (volgordes). In die zin was in het voorgaande voorbeeld ook voordat we de factor ‘activiteit’ toevoegden eigenlijk al sprake van een mixed design.
Net als bij het herhaalde-metingen design kunnen we mixed designs via de klassieke aanpak (mixed-ANOVA) of met multilevelanalyse analyseren, waarbij dezelfde overwegingen gelden. Ongeacht welke aanpak je kiest, zal je vaak geïnteresseerd zijn in het interactie-effect tussen de within- en between-subjectsfactoren.
30.10 Analyses
Wanneer we de data uit het slaapkwaliteitvoorbeeld analyseren met een RM-ANOVA, waarbij ‘activiteit’ de between-subjectsfactor is en de genoten drank de within-subjectsfactor, dan levert dit onder andere de onderstaande resultaten op. Zie tabel 30.2 voor de toetsresulaten (\(F\)-test) van zowel de within- als de between-subjectsanalyses.
| SSQ | df | MSQ | F | p | |
|---|---|---|---|---|---|
| Activity | 96 | 2 | 47.9 | 8.3 | 0.001 |
| Residual | 190 | 33 | 5.7 |
De activiteit is de between-subjectsfactor en de drie dranken vormen de within-subjectsfactor, die in deze analyse met de term ‘withinFactor’ wordt aangeduid. Bij een mixed design zoals hier, zijn we meestal vooral geïnteresseerd in de interactie tussen de within- en between-subjectsfactoren. Dat effect is hier ook statistisch significant. Verder zijn er significante hoofdeffecten van activiteit en drank.
| SSQ | df | MSQ | F | p | |
|---|---|---|---|---|---|
| RM factor Drinks | 85.0 | 2 | 42.48 | 166.6 | 0.000 |
| Drinks*Activity | 5.5 | 4 | 1.38 | 5.4 | 0.001 |
| Residual | 16.8 | 66 | 0.26 |
Tenslotte kunnen we de geschatte waarden van elke combinatie van categorieën (estimated means) ook berekenen en in een figuur laten zien. Zie figuur 30.3.
De figuur laat duidelijk zien dat binnen elke categorie van activiteit, water drinken de beste slaapkwaliteit levert, en koffie de slechtste. Voor elke drank geldt dat lezen het beste resultaat geeft en daarna fysieke oefening. De drie blokjes zijn niet precies gelijk qua structuur aan elkaar, waardoor sprake is van enige interactie tussen beide factoren (drank en activiteit), maar het is duidelijk dat die interactie zeer gering is.
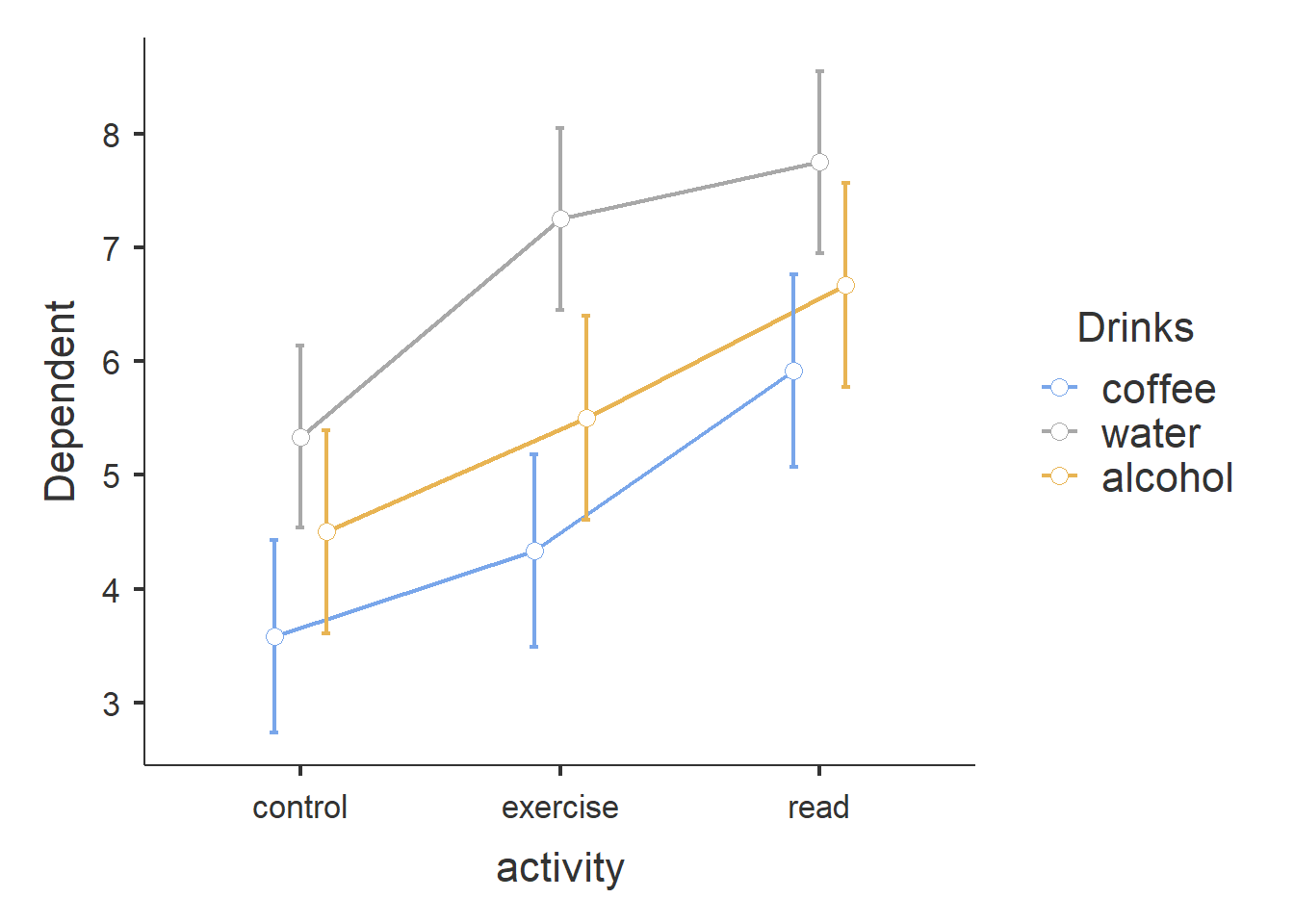
Figuur 30.3: Figuur met de geschatte gemiddelden en betrouwbaarheidsintervallen.