Hoofdstuk 15 Samenhang in data
- samenhang
- scatterplots.
- Onderzoekspracticum inleiding onderzoek (PB0212)
15.1 Inleiding
In de hoofdstukken Beschrijvingsmaten en Verdelingsvormen en -maten worden visualisaties en beschrijvingsmaten besproken die gebruikt kunnen worden om een datareeks te inspecteren. Maar in onderzoek worden bijna altijd meerdere variabelen onderzocht. Datasets bevatten dus bijna altijd meer dan één datareeks. Onderzoekers zijn meestal geïnteresseerd in hoe datareeksen samenhangen en minder in de verdelingen van enkelvoudige datareeksen.
Het onderzoeken van relaties tussen variabelen is interessant om de wereld beter te kunnen begrijpen. Als iemand op een variabele een hoge waarde heeft, scoort deze persoon dan ook hoog op een andere variabele? Stel dat bij OU-studenten hun eigeneffectiviteit met betrekking tot statistiek en het aantal uren dat ze aan de studie besteden wordt gemeten. Hangen deze twee variabelen samen? Als studenten met een hogere eigeneffectiviteit meer tijd aan de studie besteden (of juist minder), is er sprake van samenhang. Het is dan mogelijk om uit de ene variabele (eigeneffectiviteit) te voorspellen wat iemand op de andere variabele (studie-investering) scoort.
Vaak gaat de interesse zelfs nog een stap verder: leidt hogere eigeneffectiviteit tot hogere studie-investering? Dit is een vraag over oorzaak en gevolg oftewel over causaliteit (zie het hoofdstuk Causaliteit. Van alle onderzochte verbanden in de wereld, en dus ook in datasets, is slechts een fractie causaal.
Om te onderzoeken of een eventueel verband tussen eigeneffectiviteit en studie-investering causaal is, kan een experimentele studie gedaan worden. Deze studie kan eigeneffectiviteit stimuleren om daarna vast te stellen of studenten ook meer gaan studeren. Maar het kan ook zo zijn dat studenten gestimuleerd worden om meer te gaan studeren om vervolgens te bepalen of hun eigeneffectiviteit stijgt. Vaak blijkt dat geen van beide causale relaties bestaat: het geobserveerde verband wordt in dat geval verklaard door andere variabelen. In dit hoofdstuk spreken we van verbanden en laten de kwestie of deze verbanden causaal zijn of niet buiten beschouwing.
In dit hoofdstuk gebruiken we de Palmer Penguins dataset ter illustratie. Deze dataset bevat informatie over drie pinguïnsoorten. Er is meer informatie beschikbaar op https://allisonhorst.github.io/palmerpenguins.
15.2 Twee variabelen
In dit voorbeeld kijken we naar het gewicht van de pinguïns (in grammen) en de lengte van hun flippers (in millimeters). We willen weten of zwaardere pinguïns langere flippers hebben. We bekijken eerst de twee datareeksen apart: deze staan in Figuur 15.1.
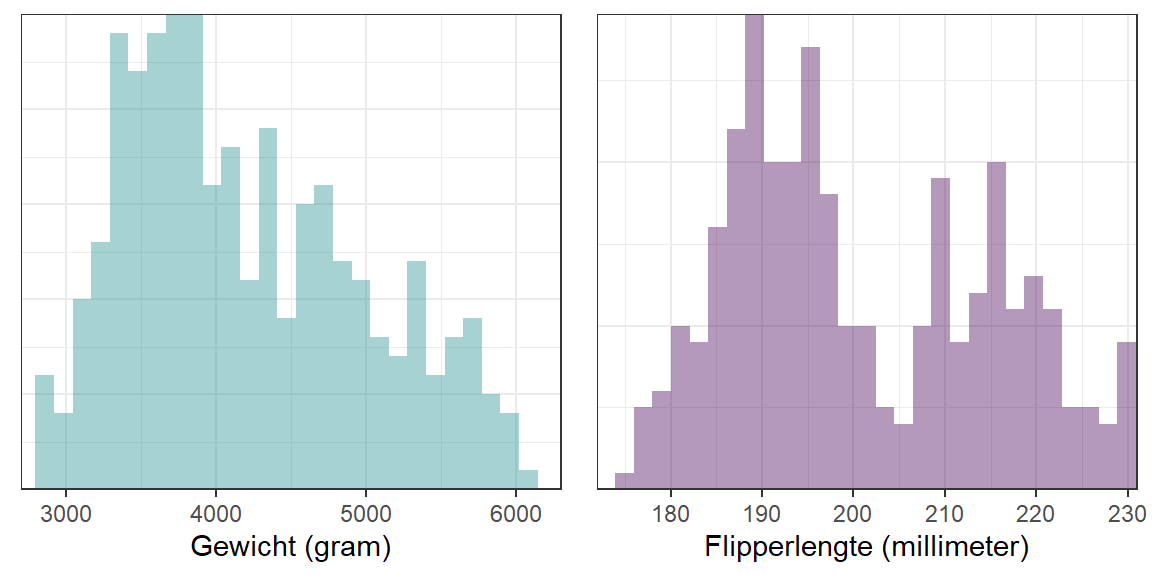
Figuur 15.1: Histogrammen voor gewicht en flipperlengte
Deze histogrammen zijn geïntroduceerd in het hoofdstuk Verdelingsvormen en -maten. Zoals daar is besproken, representeert elke staaf in zo’n histogram het aantal onderzoekseenheden (meestal deelnemers: nu pinguïns) met een bepaalde score. Maar op deze manier is het lastig om snel inzicht te krijgen in een eventueel verband. We zouden dan één voor één voor alle deelnemers (of pinguïns) moeten kijken waar ze zich in elk histogram bevinden.
We kunnen deze twee histogrammen ook combineren door het histogram van gewicht te roteren en op de \(y\)-as te plaatsen, zoals weergegeven in Figuur 15.2.
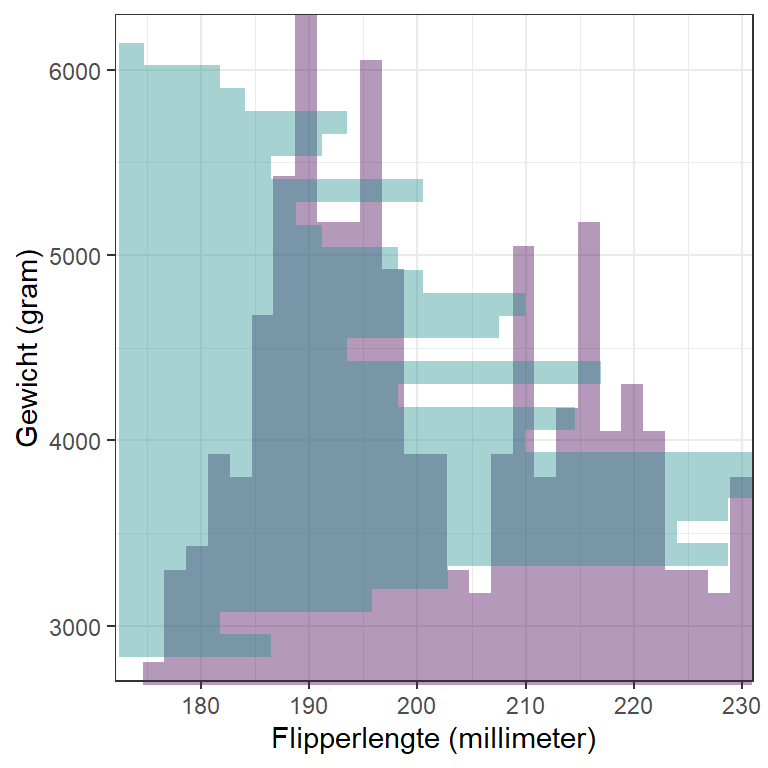
Figuur 15.2: De twee histogrammen gecombineerd
De staven staan voor (groepen) onderzoekseenheden. We kunnen dus voor elke onderzoekseenheid (elke pinguïn) een lijn trekken van hun score op beide assen en een stipje tekenen waar die lijnen elkaar kruisen, zoals hier geïllustreerd is voor twee pinguïns (Alex en Bobby) in Figuur 15.3.
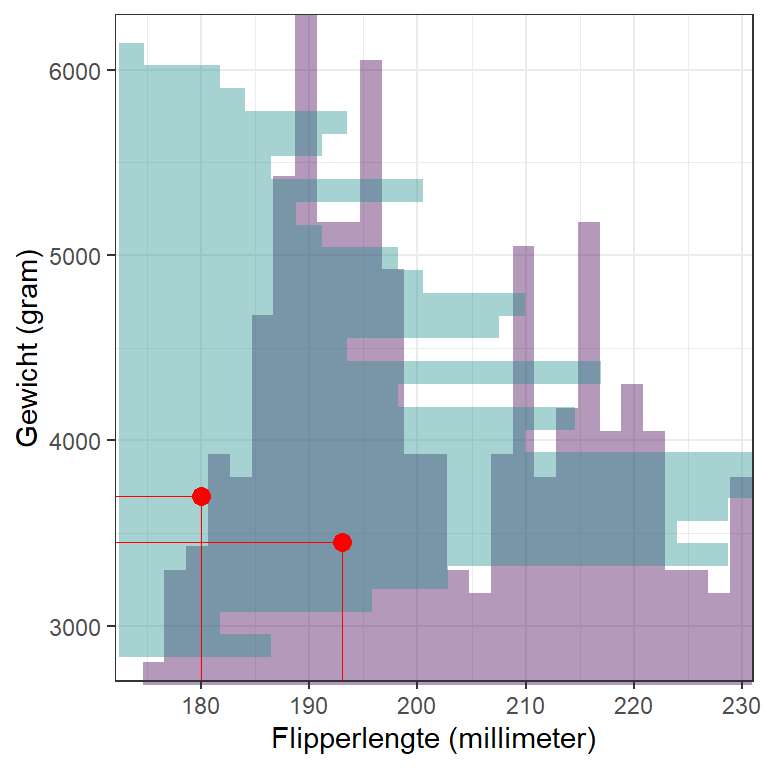
Figuur 15.3: De twee histogrammen gecombineerd, met lijnen voor twee pinguïns en puntjes waar die lijnen elkaar kruisen.
Deze lijntjes kunnen we voor alle pinguïns trekken zoals in Figuur 15.4.
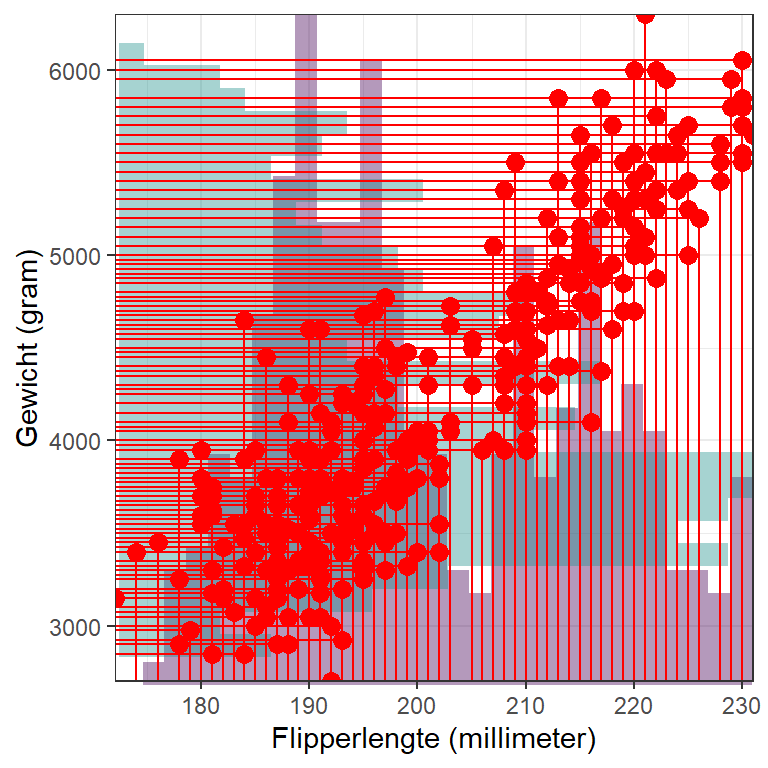
Figuur 15.4: De twee histogrammen gecombineerd, met lijnen voor elke pinguïn in de studie en puntjes waar die lijnen elkaar kruisen
Dit wordt al snel onoverzichtelijk. Daarom laten we nu de lijnen en de histogrammen weg, zoals weergegeven in Figuur 15.5.
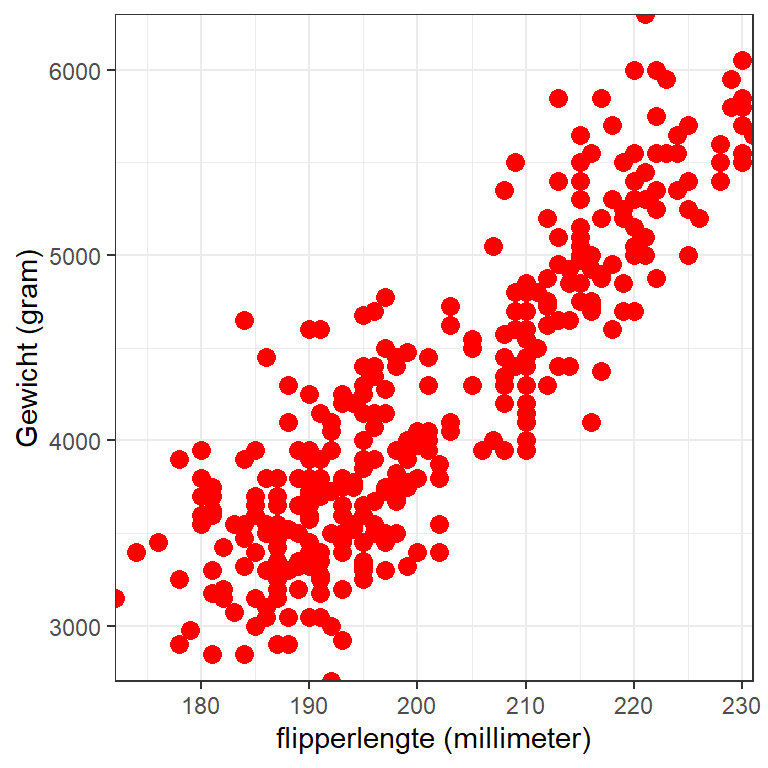
Figuur 15.5: Scatterplot voor het verband tussen flipperlengte en gewicht
15.3 Een scatterplot
Wat we te zien krijgen, heet een scatterplot. Elk stipje representeert een pinguïn – of algemener een onderzoekseenheid (meestal deelnemers bij onderzoek met mensen). De twee datapunten die bij die pinguïn horen, oftewel de twee meetwaarden van die pinguïn op de variabelen van de \(x\)- en \(y\)-as, bepalen de positie van het stipje.
15.3.1 Een positief verband
Aan deze scatterplot is te zien dat pinguïns die hoger scoren op de variabele op de \(x\)-as (flipperlengte) over het algemeen ook hoger scoren op de variabele op de \(y\)-as (gewicht) en andersom. In deze steekproef is er dus sprake van een positief verband tussen die twee variabelen. Een positief verband betekent dat naarmate de waarde van de variabele op de \(x\)-as toeneemt of afneemt, de waarde van de variabele op de \(y\)-as ook toeneemt of afneemt. Als op de \(x\)-as en de \(y\)-as twee kenmerken van onderzoekseenheden staan, dan betekent zo’n positief verband dat onderzoekseenheden die meer (minder) van het ene kenmerk hebben, vaak ook meer (minder) van het andere kenmerk hebben.
Toegepast op pinguïns staan op de \(x\)-as en de \(y\)-as twee verschillende eigenschappen van pinguïns. In dit geval betekent een positief verband dat als een pinguïn hoger scoort op de ene eigenschap (bijvoorbeeld zwaarder is), dat die pinguïn dan waarschijnlijk ook hoger scoort op de andere eigenschap (bijvoorbeeld langere flippers heeft).
Toegepast op mensen kunnen op de \(x\)-as en de \(y\)-as twee psychologische constructen staan, zoals eigeneffectiviteit met betrekking tot pinguïnsoorten onderscheiden op de \(x\)-as, en hoeveel lol iemand ontleent aan het onderscheiden van pinguïnsoorten op de \(y\)-as. Een positief verband betekent dan dat mensen die het leuker vinden om pinguïnsoorten te onderscheiden, over het algemeen ook een hogere eigeneffectiviteit hebben met betrekking tot het onderscheiden van pinguïnsoorten, en andersom.
15.3.2 Een negatief verband
Bij een negatief verband geldt dat onderzoekseenheden die hoger scoren op de variabele op de \(x\)-as, juist lager scoren op de variabele op de \(y\)-as, en andersom. Figuur 15.6 toont voor pinguïns een negatief verband tussen snavellengte en snavelhoogte.
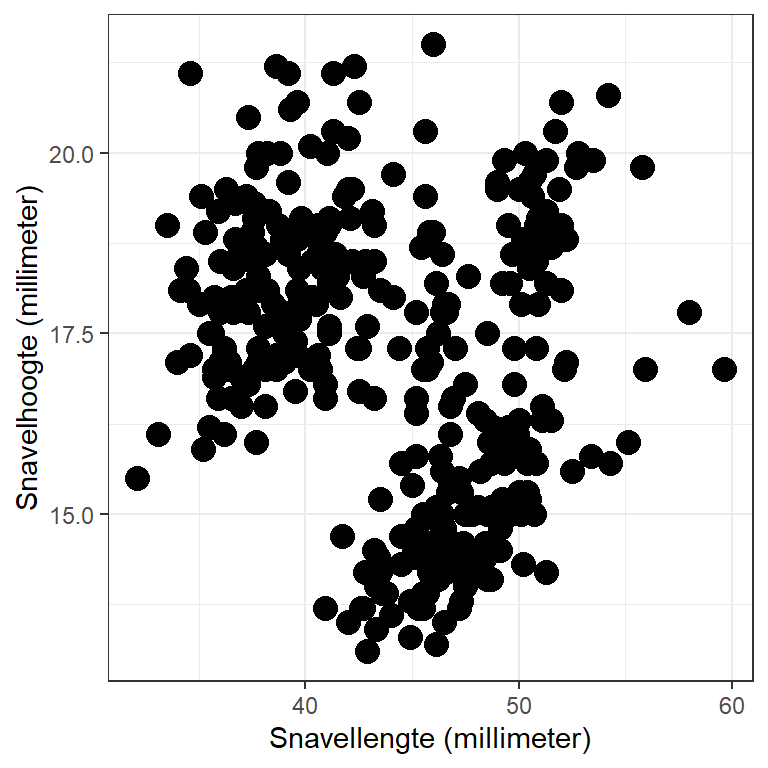
Figuur 15.6: Scatterplot voor het verband tussen snavellengte en snavelhoogte
Een voorbeeld van een negatief verband bij mensen is dat mensen die meer stress ervaren, aangeven dat ze minder gelukkig zijn (dus: hoe hoger de stress, hoe lager het geluk). Een ander voorbeeld is dat naarmate mensen meer van pizza houden, ze minder vaak maaltijden uit een Aziatische keuken eten (of andersom).
Een negatief verband betekent dus dat naarmate de ene variabele hoger (lager) is, de andere variabele lager (hoger) is. Deels is dit een kwestie van hoe je zo’n variabele definieert. ‘Voorkeur voor pizza’ kun je ook meten als ‘afkeur van pizza’ en dan wordt een negatief verband opeens positief.
15.3.3 Positieve en negatieve verbanden onderscheiden
Om te bepalen of een scatterplot een positief of een negatief verband verbeeldt, kun je een ellips inbeelden die zo getekend is dat de meeste punten erbinnen vallen. Je kunt ook een lijn inbeelden die zo goed mogelijk door de puntenwolk heen loopt. Beiden zijn getekend in deze voorbeelden.
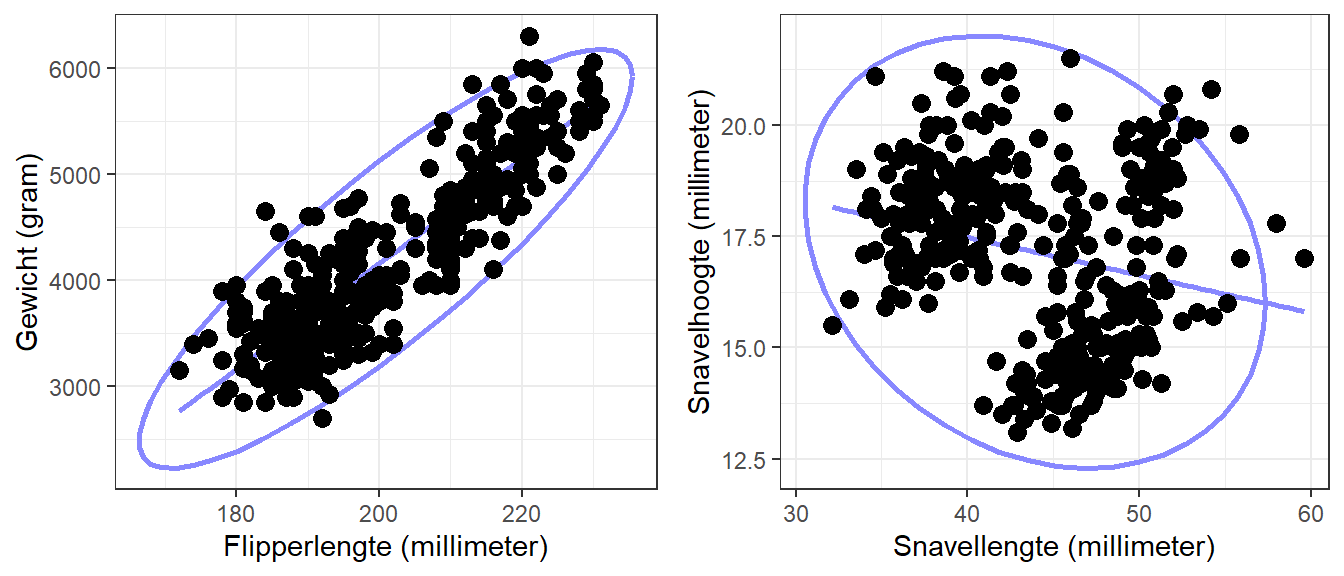
Figuur 15.7: De twee eerder getoonde scatterplots met elk een ellips en een lijn
Kortom, als een scatterplot een positief verband uitdrukt, liggen de stipjes grofweg in een wolk, of rondom een lijn, die van linksonder naar rechtsboven loopt. Als een scatterplot een negatief verband uitdrukt, liggen de stipjes grofweg in een wolk, of rondom een lijn, die van linksboven naar rechtsonder loopt. Het kan natuurlijk ook dat twee variabelen helemaal niet samenhangen. Dan is de score op de ene variabele dus niet te voorspellen uit de andere variabele. In dat geval liggen de stipjes in een ronde wolk, en loopt de lijn horizontaal, zoals in Figuur 15.8 weergegeven.
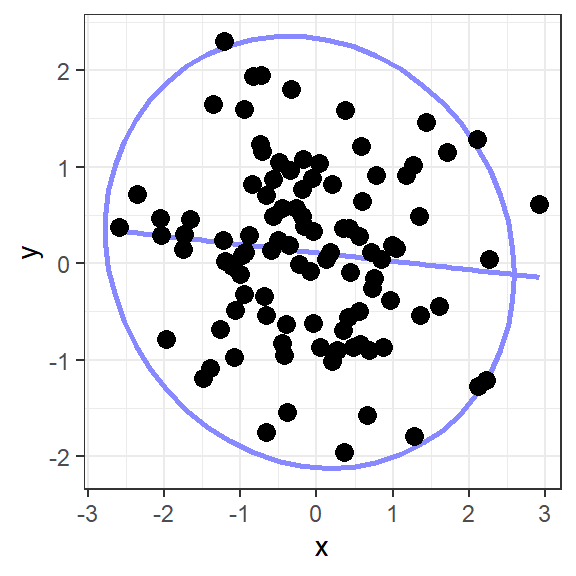
Figuur 15.8: Het verband tussen twee ongerelateerde variabelen