Hoofdstuk 26 Logistische regressie
- waarom lineaire regressie niet werkt
- het logistisch regressie model
- de odds-ratio bij logistische regressie
- de kwaliteit van het model
- aannames bij logistische regressie.
- Onderzoekspracticum cross-sectioneel onderzoek (PB0812)
26.1 Inleiding
Bij lineaire regressie is een van de voorwaarden dat de afhankelijke variabele wordt gemeten op intervalniveau. Maar het komt ook vaak voor dat we geïnteresseerd zijn in het voorspellen van een dichotome variabele, zoals of het aantal uren dat men studeert, of iemands studiemotivatie, kan voorspellen of iemand slaagt of zakt voor een statistiekmodule. Andere voorbeelden van vragen over dichotome variabelen zijn: heeft iemand een bepaalde ziekte (of niet), is iemand gestopt met roken (of niet). Logistische regressieanalyse maakt het mogelijk deze vragen te beantwoorden.
De te volgen stappen bij het analyseren van een model met logistische regressie zijn vergelijkbaar met die bij lineaire regressieanalyse. De onderliggende rekenmethode om tot de uitkomsten te komen is wel anders dan bij lineaire regressie en dat heeft gevolgen voor de interpretatie van de uitkomsten.
In dit hoofdstuk zullen we eerst de techniek illustreren aan de hand van een voorbeeld en de onderliggende theorie kort bespreken. Daarna volgt een uitgebreid minivoorbeeld van een analyse waarin de uitkomsten van de analyse met een enkele predictor voor u begrijpelijk worden gemaakt.
26.2 Waarom lineaire regressie niet werkt
Ter illustratie van een logistische regressie gebruiken we een dataset waarin we de schooluitslag willen voorspellen. In deze data is er een dichotome variabele genaamd ‘uitslag’ die de waarde \(1\) heeft als de persoon is geslaagd voor het voortgezet onderwijs zonder te zijn blijven zitten. De uitslag is \(0\) als er sprake is van doublures of wanneer de persoon is gezakt. De vraag is of we de uitslag kunnen voorspellen op basis van de leermotivatie en het IQ van de leerling. Leermotivatie is een intervalvariabele met scores tussen \(1\) (zeer lage motivatie) en \(20\) (zeer hoge motivatie).
In Figuur 26.1 is de variabele intelligentie afgezet tegen de afhankelijke variabele uitslag (geslaagd versus gezakt). Uit de figuur wordt meteen duidelijk dat het geen zin heeft om een rechte lijn proberen te schatten die zo goed mogelijk door de punten loopt. Geen enkele rechte lijn is hiervoor te bedenken en dat geldt voor elke situatie met een dichotome afhankelijke variabele. Dat is de reden dat lineaire regressie niet geschikt is om dit soort data te analyseren.
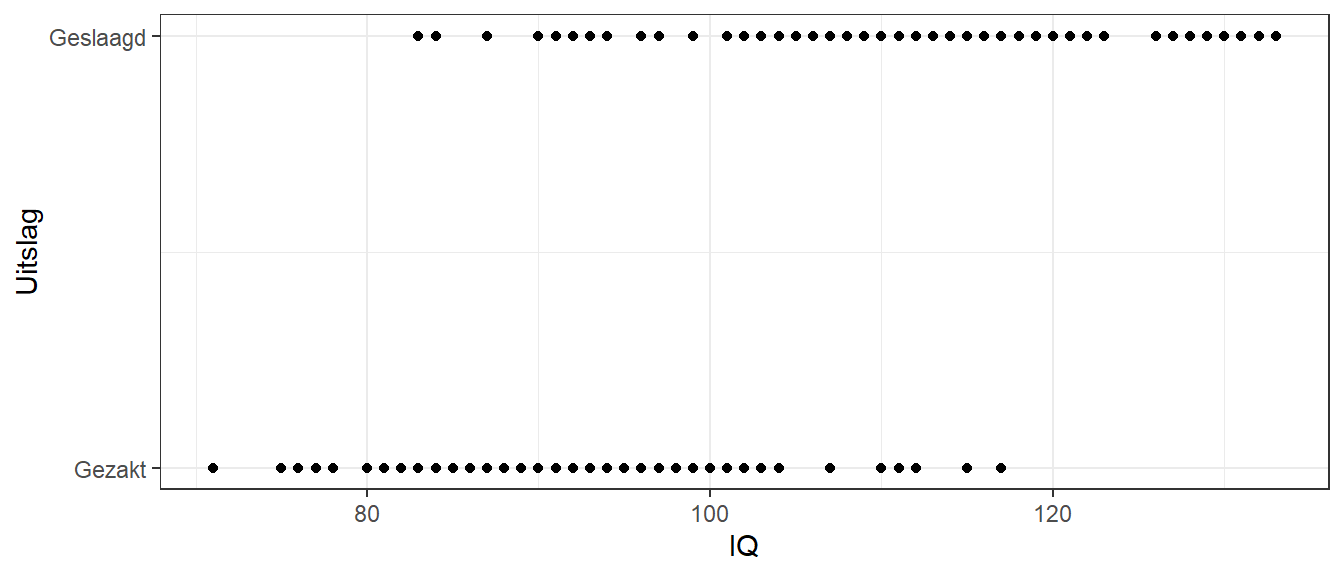
Figuur 26.1: Voorbeeld-data met een dichotome uitkomst
Een rechte lijn zou ook geen zin hebben, omdat de rechte lijn zal proberen getallen tussen \(0\) en \(1\) in te vullen die niet bestaan: men slaagt of zakt, en daar zit geen ruimte tussen die in een getal kan worden uitgedrukt. Logistische regressie lost dit probleem op door niet de uitkomst (slagen of zakken) zelf te proberen te berekenen, maar de kans op slagen of zakken. In plaats van een rechte lijn wordt een zogenaamde S-curve gebruikt die een platte bodem heeft bij \(0\) en een plat plafond bij \(1\), zie Figuur 26.2.
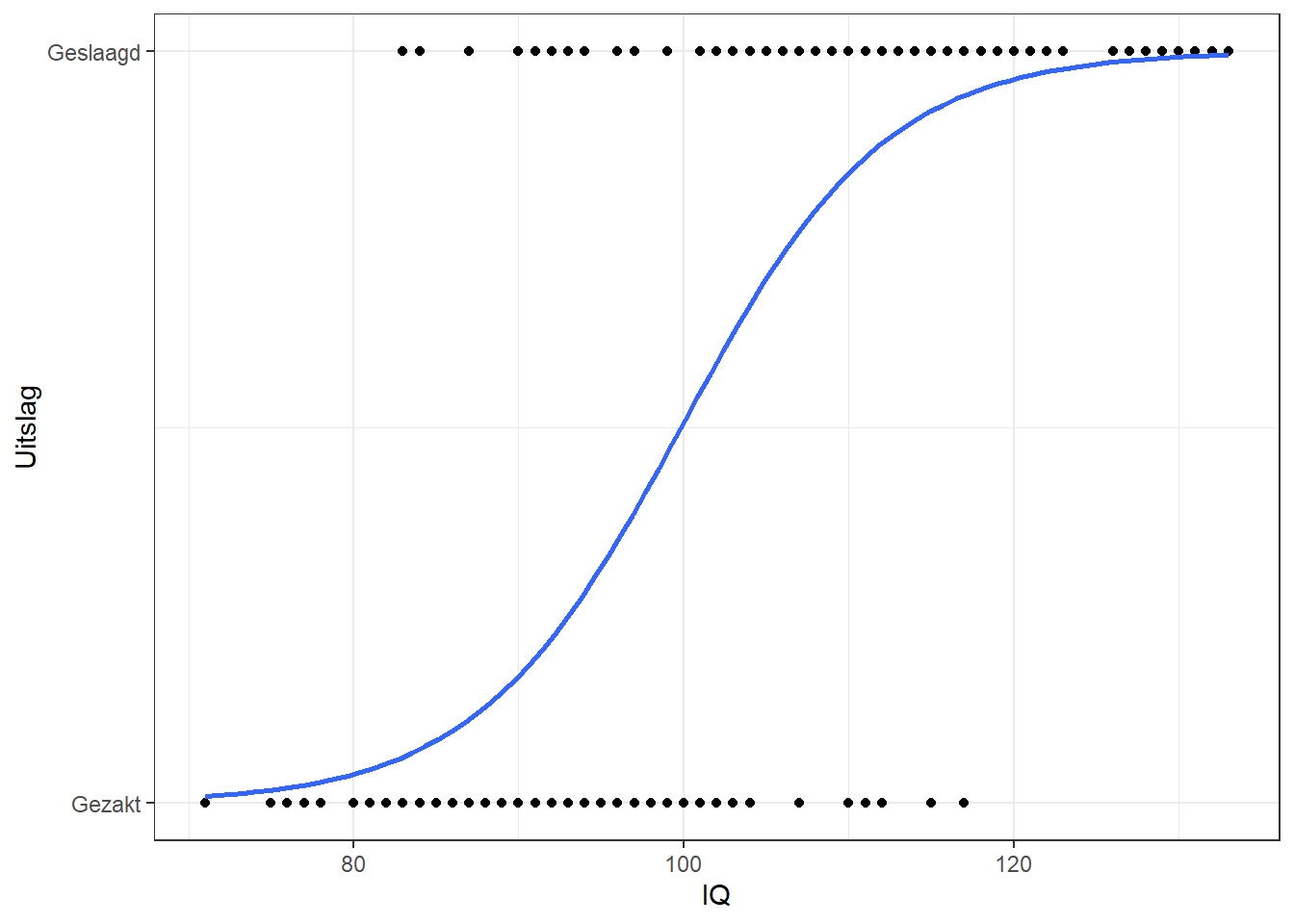
Figuur 26.2: Voorbeeld-data met een dichotome uitkomst en logistische curve
Deze kromme lijn geeft de kans op de waarde \(1\) weer: in dit geval de kans op slagen op basis van het IQ. Omdat een kans per definitie tussen de \(0\) en \(1\) ligt past zo’n kromme lijn in het bereik van de data. In de figuur zien we bijvoorbeeld dat iemand met een IQ van \(100\) ongeveer \(50\%\) kans heeft om te slagen. Figuur 26.3 geeft dezelfde kromme weer als die in Figuur 26.2, maar nu met de verdeling van de datapunten weergegeven in de figuur en op de y-as de kans op slagen.
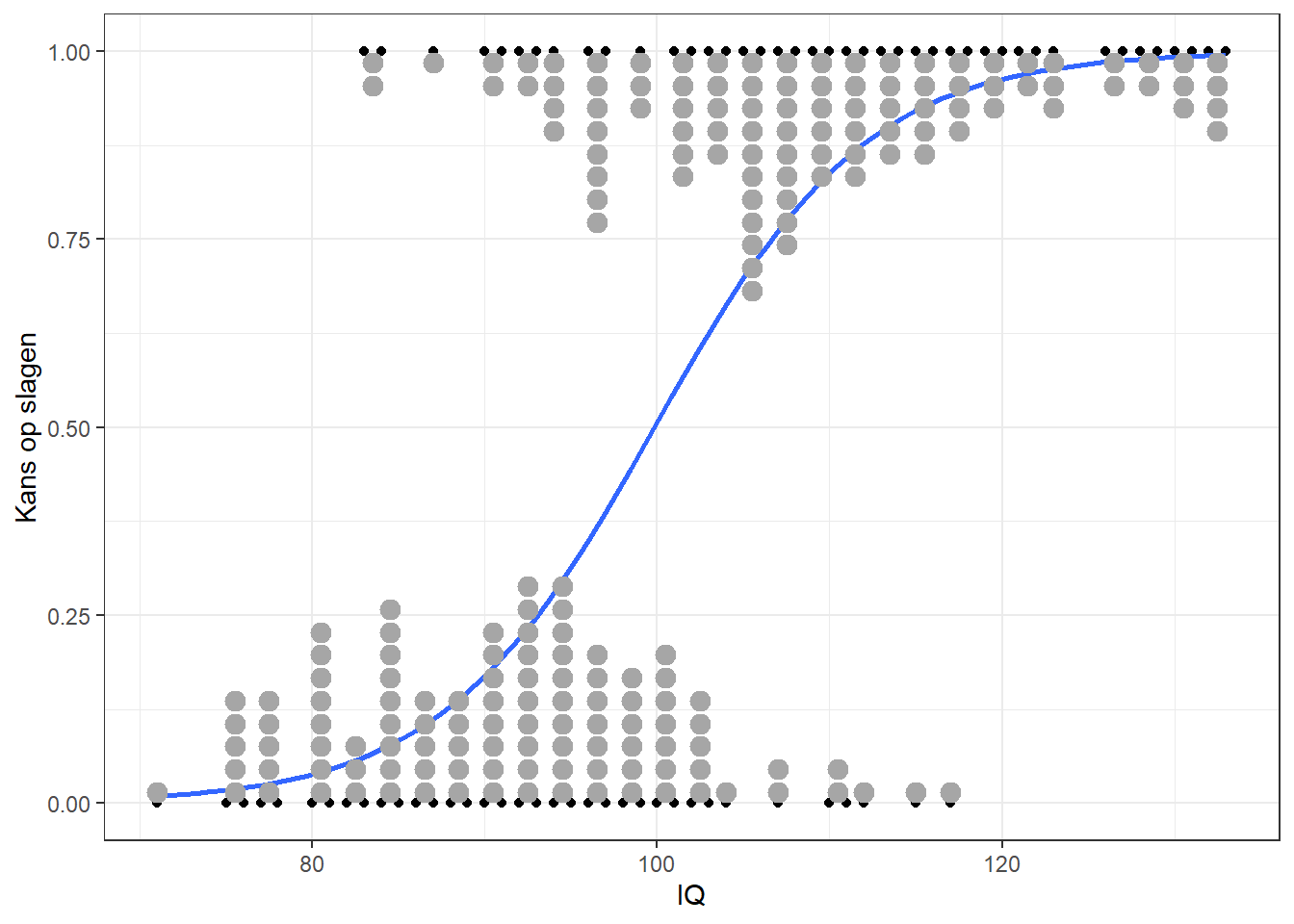
Figuur 26.3: Voorbeeld-data met een dichotome uitkomst en logistische curve
Omdat logistische regressie geen lineaire functies opstelt, zijn de regressievergelijkingen die de uitkomsten moeten beschrijven ingewikkelder dan in lineaire regressie het geval is. Hierdoor wijkt de output van logistisch regressie af van die van lineaire regressie, en worden er andere termen gebruikt dan bij lineaire regressie.
26.3 Het logistisch regressie model
In deze sectie gaan we dieper in op het logistische model. Om het model uit te leggen hebben we enige elementaire wiskunde nodig, zoals de logaritme en de \(e\)-macht. Hierboven is beschreven dat we kansen voorspellen in plaats van \(0\) en \(1\). Een kans (\(p\)) heeft altijd een waarde die tussen \(0\) en \(1\) ligt, dus hiermee hebben we meer flexibiliteit dan door enkel een \(0\) of een \(1\) te willen voorspellen. Maar ook een kans met harde grenzen bij \(0\) en \(1\) is niet een geschikte afhankelijke variabele voor schattingsmethode die gebaseerd is op een lineair model, omdat er bij een lineaire model er geen harde afkappunten zijn, zoasl \(0\) en \(1\). De kans wordt daarom meestal zodanig getransformeerd dat de getransformeerde variabele wel geschikt is voor een lineair model. De meest voorkomende transformatie die hierbij wordt gebruikt is de zogenaamde logistische transformatie:
\[\begin{equation} \bar{y} = \log\frac{p}{(1-p)} \tag{26.1} \end{equation}\]
Deze formule geeft een kansverhouding weer: dat wil zeggen de kans op ‘geslaagd’ of \(1\) (\(p\)) gedeeld door de kans op ‘gezakt’ of \(0\) (\(1 - p\)). In het Engels wordt dit de ‘odds’ genoemd. Vervolgens wordt de (natuurlijke) logaritme van de odds genomen (aangegeven met \(\log\)), de zogenaamde ‘log-odds’, die elke waarde tussen plus en min oneindig kan aannemen. Deze log-odds is nu wel geschikt voor een schattingsmethode en kan worden gebruikt als afhankelijke variabele in een logistische regressie. De regressievergelijking van een logistisch model met twee predictoren, ziet er als volgt uit:
\[\begin{equation} \log\frac{p}{1-p} = \hat{y} = a + b_1 x_1 + b_2 x_2 + \epsilon \tag{26.2} \end{equation}\]
Hierbij zijn \(x_1\) en \(x_2\) predictoren en \(b_1\) en \(b_2\) de bijbehorende regressiecoëfficiënten. Verder is \(a\) het intercept (de constante) en geeft de term \(\epsilon\) de random error of het residu aan. We kunnen de uit het model voorspelde log-odds terugrekenen naar een kans op succes (in dit geval geslaagd zijn) aan de hand van de volgende formules:
\[\begin{equation} \text{odds} = \frac{p}{1-p} = \exp(\hat{y}) \tag{26.3} \end{equation}\]
Hierbij verwijst de ‘\(\exp\)’ (exponent, de omgekeerde bewerking van de natuurlijke logaritme) naar \(e\), het grondgetal van de natuurlijke logaritme (afgerond \(2.72\)). Uiteindelijk wordt de kans op succes:
\[\begin{equation} p = \frac{\text{odds}}{1 + \text{odds}} = \frac{1}{1 + \exp(- \hat{y})} \tag{26.4} \end{equation}\]
Odds zijn subtiel, maar essentieel anders dan kansen. Een kans is een verhouding van een mogelijke uitkomst met het totaal van alle mogelijkheden. De kans op een zes te gooien op een dobbelsteen is \(1\) (want er is maar een manier om een zes te gooien op een dobbelsteen) gedeeld door alle mogelijke uitkomsten, dus \(1/6\), want er zijn zes getallen op een dobbelsteen. Een odds is een verhoudingsmaat tussen een gebeurtenis en de overige gebeurtenissen. De odds op een zes gooien met een dobbelsteen is \(1\) tegen \(5\).
In bijvoorbeeld een kaartspel met \(52\) kaarten, waarbij ieder type kaart vier maal voorkomt (zoals vier heren, of vier azen) is de kans om de eerste keer een aas te trekken:
\[\begin{equation} p(\text{Aas}) = \frac{4}{52} = 4:52 = 1:13 = 0.077 = 7.7\% \tag{26.5} \end{equation}\]
De odds om een aas de eerste keer uit een vol pak kaarten te trekken is:
\[\begin{equation} \text{Odds}(\text{Aas}) = 4:(52 -4) = 4:48 = 1:12 \text{(uitgesproken als 1 tegen 12)} \tag{26.6} \end{equation}\]
Voor iedere aas zijn er \(12\) niet-azen in het pak kaarten. De verwachting is dat het \(12\) maal waarschijnlijker is om geen aas te trekken dan wel een aas. In de wereld van het gokken, zoals paardenraces worden odds vaak als intuïtievere waarschijnlijkheidsmaten gezien dan kansen.
De odds kunnen als een verhouding worden weergegeven. Deze verhouding, ook wel odds-ratio genoemd is in de output van een logistische regressie af te lezen. De \(1\) tegen \(12\) uit het kaartspelvoorbeeld kan op twee manieren worden uitgedrukt, als \(1/12e (=0.083)\) of als \(12/1e (=12)\). Deze getallen zien er op papier radicaal anders uit, maar betekenen vrijwel hetzelfde. Om deze twee getallen te lezen is het handig om de volgende drie regels te onthouden:
- Een odds van \(1\) of hoger wordt anders gelezen dan een odds lager dan \(1\)
- Een odds van \(1\) of hoger betekent dat de gunstige uitkomst X-maal vaker gebeurt dan de ongunstige uitkomst
- Een odds lager dan \(1\) betekent dat de gunstige uitkomst X-maal minder vaak gebeurt dan de ongunstige uitkomst
26.4 De odds-ratio bij logistische regressie
De interpretatie van de regressie coëfficiënten is in het logistisch model dus veel complexer dan bij gewone multiple regressie. Bij gewone multiple regressie heeft de waarde \(b_1\) de volgende betekenis: bij een stijging in \(x_1\) met een eenheid (en alle andere variabelen gelijkblijvend) stijgt de voorspelling van y met \(b_1\) eenheden. Bij logistische regressie betekent een stijging in \(x_1\) dat de log-odds met \(b_1\) stijgen. Omdat het erg lastig is om een stijging van een logaritme van een kansverhouding (log-odds) te interpreteren wordt dit meestal niet gedaan, maar wordt simpelweg gekeken of de parameter \(b\) significant is en of deze de log-odds doet stijgen (de kans op de gebeurtenis neemt toe als \(b > 0\)) of dalen (\(b < 0\)).
Voor de interpretatie van de regressiecoëfficiënten wordt ook de exponent van de coëfficiënten (\(e^b\), meestal geschreven als \(\exp(b))\) berekend en standaard weergegeven in de output van een logistische regressie analyse. Om te begrijpen wat deze term voorstelt, geven we de odds (kansverhouding) van een simpele vergelijking voor een willekeurige waarde \(x\) en voor \(x+1\):
\[\begin{equation} odds(x) = e^{a + b x} = \text{exp}(a + b x) \tag{26.7} \end{equation}\]
\[\begin{equation} odds(x+1) = e^{a + b(x+1)} = \text{exp}(a + b (x + 1)) \tag{26.8} \end{equation}\]
Wanneer we de verhouding van deze twee nemen dus \(\text{odds}(x+1)\) delen door \(\text{odds}(x)\) dan geeft dat met behulp van basale middelbare school wiskunde het volgende resultaat:
\[\begin{equation} \frac{\text{odds}(x+1)}{\text{odds}(x)} = \frac{\text{exp}(a + b(x+1))}{\text{exp}(a + b(x))} = \text{exp}(a + b(x+1) - a - b(x)) = \text{exp}(b) \tag{26.9} \end{equation}\]
Deze verhouding wordt de odds-ratio genoemd, een verhouding tussen twee odds. Een odds-ratio die groter is dan \(1\) (\(b > 0\) waardoor odds-ratio \(e^b > 1\))houdt een toename van de odds in, een odds-ratio tussen \(0\) en \(1\) (\(b < 0\) waardoor odds-ratio \(e^b < 1\)) een afname. De interpretatie van een \(\exp(b)\) is nu als volgt: wanneer de bijbehorende \(x\) een eenheid stijgt, dan neemt kansverhouding (odds) met \(\exp(b)\) toe.
In het onderstaande voorbeeld wordt een en ander nogmaals stapsgewijs uitgelegd.
26.5 Een voorbeeld: schoolsucces
Als voorbeeld nemen we de data die hierboven werd getoond. Stel we willen voorspellen of iemand slaagt (Uitslag = \(1\)) op basis van zijn IQ score. IQ is hier de predictor en uitslag de afhankelijke variabele in een logistische regressie.
Dit model ziet er als volgt uit.
\[\begin{equation} \log\frac{p(uitslag = 1)}{1-p(uitslag = 1)} = a + b_1 IQ \tag{26.10} \end{equation}\]
Dit model geeft twee coëfficiënten, een voor het intercept en een voor IQ. De waarden van deze coëfficiënten zijn respectievelijk \(-16.15\) en \(0.16\). Met deze coëfficiënten en een bepaalde waarde van de variabele IQ (bv \(100\)) kan ook een log-odds worden voorspeld.
\[\begin{equation} \log\frac{p(uitslag = 1)}{1-p(uitslag = 1)} = -16.15 + 0.16 IQ \tag{26.11} \end{equation}\]
Vul de waarde \(100\) in voor IQ om de log-odds te berekenen voor iemand met een IQ score van \(100\).
\[\begin{equation} \log\frac{p}{1-p } = -16.15 + 0.16(100) = 0.05 \tag{26.12} \end{equation}\]
En vervolgens kan hieruit de kans op slagen worden afgeleid, eerst door de odds te berekenen als exponent van de log-odds: \(exp(0.05) = 1.05\).
\[\begin{equation} p = \frac{\text{odds}}{1 + \text{odds}} = \frac{1.05}{1 + 1.05} = 0.51 \tag{26.13} \end{equation}\]
De kans op slagen voor iemand met een IQ van \(100\) is dus \(51\%\). Op deze manier kunnen we voor iedere IQ score (iedere persoon) een kans op slagen voorspellen. Deze kansen kunnen we vervolgens plotten in een figuur met IQ op de x-as.
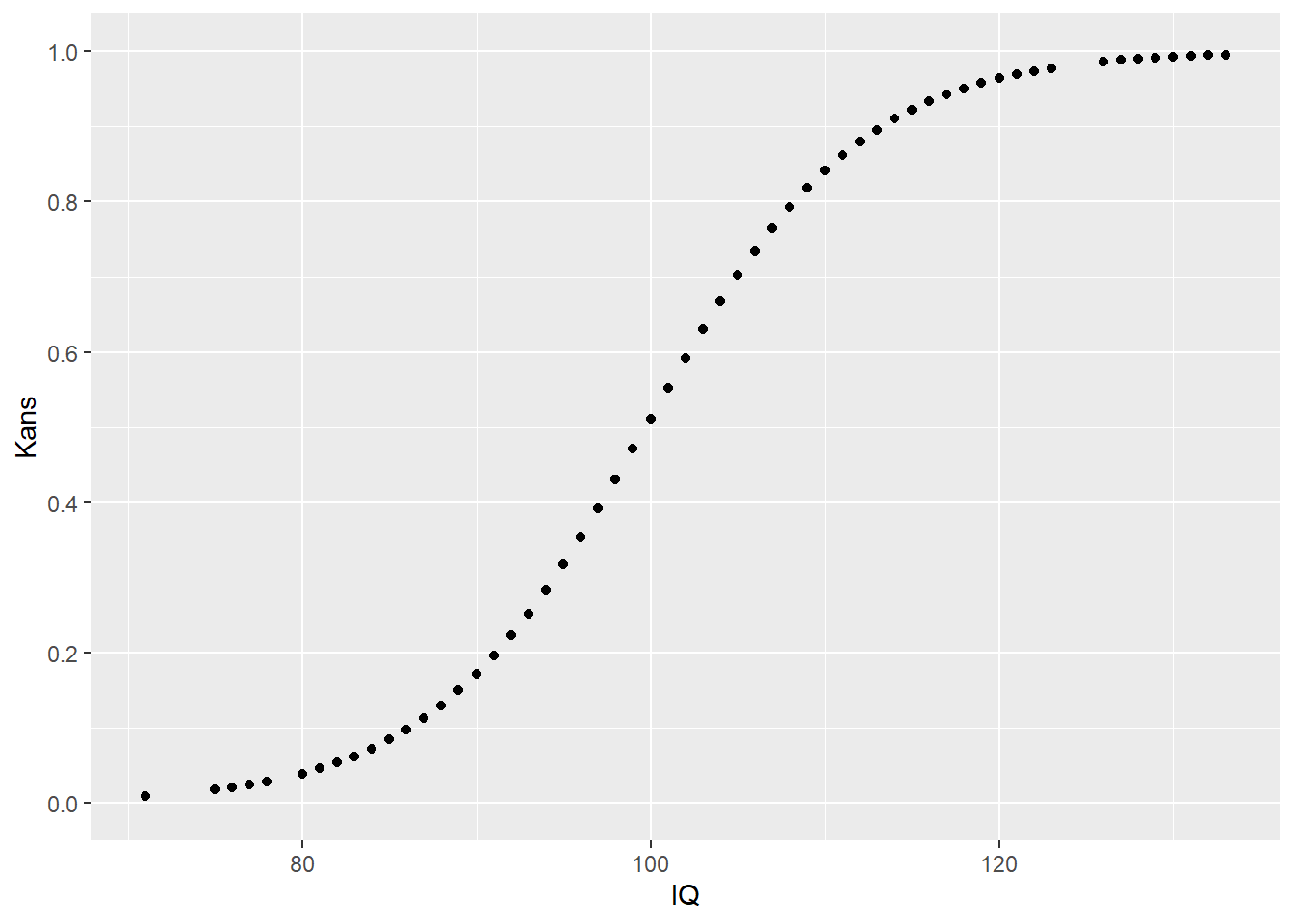
Figuur 26.4: Voorspelde kans op slagen
Om de betekenis in te zien van de exponenten van de coëfficienten \(\exp(b_1)\) (in dit voorbeeld \(\exp(0.16)\) = \(1.18\)), berekenen we ook de odds voor een paar andere waarden van IQ. Zo is de odds voor \(\text{IQ} = 100\) gelijk aan \(1.05\), en voor IQ \(101\), \(102\) en \(103\) respectievelijk \(1.231\), \(1.448\) & \(1.702\) en dit kunnen we voor elke waarde van IQ doen. Tabel 26.1 toont de odds voor een aantal waarden van IQ.
| IQ | odds | odds_ratio |
|---|---|---|
| 99 | 0.89 | 1.2 |
| 100 | 1.05 | 1.2 |
| 101 | 1.23 | 1.2 |
| 102 | 1.45 | 1.2 |
| 103 | 1.70 | 1.2 |
| 104 | 2.00 | 1.2 |
| 105 | 2.35 | 1.2 |
De ratio van de odds voor \(IQ = 101\) ten opzichte van de odds voor \(IQ = 100\) is \(\frac{1.23}{1.05} = 1.18\) en de ratio van de odds voor \(IQ = 102\) ten opzichte van de odds voor \(IQ = 101\) is \(\frac{1.45}{1.23} = 1.18\). En ook de ratio van de odds voor \(IQ = 103\) ten opzichte van de odds voor \(IQ = 102\): die is \(\frac{1.7}{1.45} = 1.18\). Er geldt dat voor alle opeenvolgende stappen de verhouding van de odds gelijk is, namelijk gelijk aan \(\exp(b_1) = 1.18\). Dit getal geeft dus de verhouding weer van de odds bij opeenvolgende stappen van de predictor. Verhogen we de predictor met 1, dan neemt de kansverhouding (odds) toe met \(\exp(b_1)\).
Met ander woorden, het logistische model geeft schattingen van odds zodanig dat de verhouding tussen opvolgende odds (odds-ratio’s) constant is (i.c. \(1.18\)). Wat dit inhoudelijk wil zeggen is dat met de toename van een enkele schaalwaarde op IQ de odds op succes met een (multiplicatieve) factor van \(1.18\) vermeerdert.
26.6 Kwaliteit van het model
Het geformuleerde model met IQ als predictor levert voor iedere persoon een succeskans op. Een manier om te inspecteren hoe goed het model bij de data past is om de succeskansen te vergelijken met de daadwerkelijke uitslagen. Hiervoor wordt een classificatietabel gebruikt. Stel we vergelijken mensen met een voorspelde kans groter dan \(50\%\) om te slagen met hun daadwerkelijke slaagpercentage, en evenzo doen we dit voor mensen met een voorspelde slaagkans kleiner dan \(50\%\). We kunnen ook een ander percentage kiezen als classificatiecriterium voor slagen versus zakken. Dit geeft bijvoorbeeld de volgende twee tabellen. de rijen geven de geobserveerde aantallen gezakten en geslaagden aan. De kolommen geven de voorspelde gezakten en geslaagden aan, gegeven een bepaald criterium, zoals een voorspelde slaagkans van boven de \(50\%\).
| <50% kans: gezakt | >50% kans: geslaagd | |
|---|---|---|
| Gezakt | 82 | 20 |
| Geslaagd | 22 | 76 |
| <70% kans: gezakt | >70% kans: geslaagd | |
|---|---|---|
| Gezakt | 95 | 7 |
| Geslaagd | 33 | 65 |
Het percentage correct geclassificeerde personen is in de eerste tabel \(79%\) en in de laatste tabel \(80%\). Het percentage correcte classificaties is dus een maat voor de kwaliteit van het model, die wel afhangt van het criterium (grenswaarde) dat wordt gehanteerd om te beslissen of iemand de voorspelling geslaagd, dan wel gezakt krijgt.
Naast het percentage correct geclassificeerd zijn er nog meerdere criteria waarmee kan worden vastgesteld of het gehele model slecht of goed past. Een onomstreden criterium is de Chi-kwadraat goodness of fit toets. De maat wordt bepaald op grond van twee loglikelihoods, en wordt “–2 Log Likelihood” of de “deviance” genoemd. Hierbij wordt het hierboven opgestelde logistisch regressiemodel vergeleken met een model dat slechts een enkele constante bevat. Zo’n “leeg” model geeft in dit geval een deviance van \(277.18\). Het hierboven opgestelde regressiemodel, met IQ als predictor, geeft een verbetering tot \(173.81\), waarbij geldt hoe lager de waarde hoe beter het model past. Dit is een verbetering van \(103.37\), hetgeen in een chi-kwadraat toets (\(df = 1\)) significant is. De conclusie is dan ook dat het toevoegen van de predictor “IQ” tot een significante verbetering in voorspelling leidt.
Logistische regressie analyse kent geen proportie verklaarde variantie (\(R^2\)), zoals die bij een lineair regressie model gedefinieerd is. Wel bestaan er verschillende pseudo \(R^2\) maten, die zo veel mogelijk vergelijkbaar zijn met de \(R^2\) van de lineaire regressie. De meest gebruikte pseudo \(R^2\) maat is Nagelkerke’s \(R_n^2\). In dit voorbeeld, voor Nagelkerke’s \(R_n^2\) geldt: \(R_n^2\) = 0.54.
26.7 Aannames bij logistische regressie
Ten opzichte van lineaire regressie is logistische regressie analyse meer flexibel, omdat deze analyse geen aannames maakt over de verdeling van de residuen. In tegenstelling tot lineaire regressieanalyse geldt niet dat de residuen normaal verdeeld hoeven te zijn. Tenslotte wordt er geen lineair verband verondersteld tussen een predictor en de afhankelijke variabele.
Er zijn echter wel andere aannames bij logistische regressie. Een onderzoeker dient eerst te controleren of ook daadwerkelijk aan deze aannames is voldaan.
26.7.1 Lineariteit van de logit
In tegenstelling tot multipele regressie is er geen aanname dat predictoren een lineair verband hebben met de afhankelijke variabele. Echter, logistische regressie neemt aan dat er een lineair verband is tussen de continue predictoren en de logistische transformatie van de afhankelijke variabele (de zogenaamde ‘logit’).
26.7.2 Afwezigheid van multicollineariteit
Net als alle regressieanalyse is logistische regressie zeer gevoelig voor zeer hoge correlaties tussen predictoren. Hoge multicollineariteit verhoogt van minstens \(1\) van multicollineaire predictoren de kans op een type-2 fout: dat wil zeggen dat je de kans loopt om een bestaand effect te missen. Soms zit er weinig anders op dan om minstens een van zulke hoog correlerende variabelen uit het model te verwijderen.
26.7.3 Afwezigheid van ‘influential cases’
Soms zijn er uitbijters (of ‘outliers’) die de regressielijn naar zich toetrekken. Dit kan bijvoorbeeld het geval zijn als een of enkele individuele observaties zeer slecht voorspeld worden door het regressiemodel; een observatie die in werkelijkheid in de ene categorie zit, kan in het model een hoge kans toebedeeld krijgen om in de andere categorie te zitten. Als er relatief veel observaties zijn waarbij dit soort misclassificaties bij plaatsvinden, dan is het logistisch regressiemodel geen goed model om de data mee te beschrijven. Het model wordt dan naar die ‘influential cases’ toegetrokken.
26.7.4 Onafhankelijkheid van residuen
Er wordt vanuit gegaan dat alle observaties onafhankelijk van elkaar zijn. Dat betekent bijvoorbeeld dat iedere deelnemer slechts eenmaal in de analyse is opgenomen, en dat deelnemers niet zijn geworven op scholen of organisaties (en dus meer met elkaar gemeen hebben dan met willekeurige andere deelnemers). De datapunten bevatten geen herhaalde metingen binnen individuen, en de dichotome uitkomstvariabele bestaat uit wederzijds uitsluitende categorieën, zodat iemand niet in beide categorieën kan vallen. Als deze assumptie wordt geschonden neemt de kans op Type-1 fout toe, dat wil zeggen dat je mogelijk ten onrechte denkt een effect te hebben gevonden.