Hoofdstuk 24 Variantieanalyse
- one-way variantieanalyse
- de rationale van de F-toets
- contrasten
- post-hoc-testen
- kanskapitalisatie
- de interpretatie van de parameterschattingen
- Onderzoekspracticum inleiding onderzoek (PB0212)
- Onderzoekspracticum experimenteel onderzoek (PB0422)
24.1 Inleiding
Dit hoofdstuk behandelt one-way ANOVA. ANOVA staat voor analysis of variance, oftewel variantieanalyse. One-way ANOVA is een logische uitbreiding op de onafhankelijke \(t\)-toets, die de nulhypothese toetst dat twee groepsgemiddelden gelijk zijn. One-way ANOVA gebruik je om meer dan twee groepsgemiddelden met elkaar te vergelijken. De \(t\)-toets kun je dus zien als een speciaal geval van one-way ANOVA, namelijk wanneer er slechts twee groepen vergeleken worden. De naam variantieanalyse is mogelijk verwarrend omdat het gaat om de analyse van de verschillen tussen gemiddelden.
De term one-way betekent dat er in deze analyse alleen een enkele predictorvariabele en een enkele afhankelijke variabele worden betrokken. De afhankelijke variabele is altijd een numerieke (kwantitatieve) variabele en de (categorische) predictorvariabele geeft een groepsindeling aan.
De \(F\)-toets die hoort bij ANOVA, soms een exacte \(F\)-test genoemd, toetst of de gemiddelden van een kwantitatieve variabele van meerdere groepen van elkaar verschillen. ANOVA is bijvoorbeeld geschikt om te toetsen of psychologen, juristen en onderwijskundigen gemiddeld genomen verschillen in hun liefde voor reality-tv. De nulhypothese waartegen getoetst wordt, is dat alle gemiddelden gelijk zijn.
Een significante \(F\)-toets geeft aan dat niet alle gemiddelden aan elkaar gelijk zijn, maar specificeert niet welke gemiddelden precies van elkaar verschillen. Om die reden wordt de \(F\)-toets ook wel de omnibustoets genoemd. Als we willen weten welke gemiddelden – of anders gezegd welke groepen – van elkaar verschillen, kunnen we een aanvullende analyse doen met zogenaamde post-hoc-testen. Als we van tevoren al bedenken welke groepen we precies met elkaar willen vergelijken, gebruiken we zogenaamde contrasten.
Dit hoofdstuk gaat eerst in op de logica achter ANOVA. Daarna komen kort de achterliggende aannamen bij het uitvoeren van one-way ANOVA aan bod en worden twee effectmaten behandeld die de effectgrootte bij one-way ANOVA beschrijven. Een effectmaat bij ANOVA is een gestandaardiseerde maat om het verschil in groepsgemiddelden aan te geven, rekening houdend met de varianties binnen de groepen. Hierna leggen we uit hoe je specifieke groepsverschillen kunt analyseren. Ook gaan we in op hoe ANOVA de kans beperkt dat je ten onrechte de nulhypothese verwerpt vanwege kanskapitalisatie. Tenslotte wordt de analyse met one-way ANOVA en de interpretatie van de parameterschattingen geïllustreerd aan de hand van een voorbeeld.
24.2 De logica achter ANOVA
De \(F\)-toets die hoort bij ANOVA, soms een exacte \(F\)-test genoemd, toetst dus of de gemiddelden van een kwantitatieve variabele van meerdere groepen van elkaar verschillen. ANOVA lijkt qua doel daarom erg op de \(t\)-toets of de \(z\)-toets en is ook bedacht als een variant van deze toetsen. De \(t\)- en de \(z\)-toets hebben als beperking dat ze slechts twee groepen met elkaar kunnen vergelijken. ANOVA kan twee of meer groepsgemiddelden vergelijken. Om de logica achter ANOVA te begrijpen, helpt het om de formule van de \(z\)-toets weer voor de geest te halen, inclusief de beperkingen die deze toets heeft.
De \(z\)-waarde voor de \(z\)-toets wordt als volgt berekend.
\[\begin{equation} z = \frac{\bar{X} - \mu}{\sqrt{\frac{\sigma^2}{N}}} \tag{24.1} \end{equation}\]
Hierbij drukt \(\bar{X}\) het gemiddelde van de steekproef uit en \(\mu\) het populatiegemiddelde waartegen getoetst wordt. De \(\sigma^{2}\) staat voor de variantie in de afhankelijke variabele, waarbij in een \(z\)-toets wordt aangenomen dat deze populatievariantie bekend is. De \(N\) staat voor de steekproefgrootte.
De \(z\)-waarde is een elegante manier om een ruw verschil tussen twee waarden te standaardiseren. Zonder de schaal te kennen is het onmogelijk om een ruw verschil tussen twee getallen als groot of klein te duiden. Door te delen door de standaarddeviatie, of in de meeste gevallen door de standaardfout, – in bovenstaande formule uitgedrukt als de populatievariantie gedeeld door de steekproefgrootte – drukken we het verschil uit in het aantal standaarddeviaties dat twee observaties van elkaar verschillen. Een \(z\)-waarde van \(2\) betekent dus dat twee gemiddelden twee standaarddeviaties van elkaar verschillen. Met wat complex rekenwerk, of simpel zoekwerk in een \(z\)-waardentabel, kan afgeleid worden dat een \(z\)-waarde van ongeveer \(2\) de top \(5\%\) van de populatie beschrijft.
De formule van de \(t\)-toets is nagenoeg identiek aan die van de \(z\)-toets. Het verschil zit erin dat er niet tegen populatieparameters getoetst wordt, maar dat er twee steekproefgemiddelden vergeleken worden (24.2).
\[\begin{equation} t = \frac{\bar{X_1} - \bar{X_2}}{\sqrt{ \frac{s^2}{N_1} + \frac{s^2}{N_2} }} \tag{24.2} \end{equation}\]
Net als bij de \(z\)-toets blijft het basisidee van de \(t\)-toets dat twee gemiddelden van elkaar worden afgetrokken. De logica hierachter is dat als de twee gemiddelden perfect identiek zijn, zoals verondersteld in de (standaard) nulhypothese, het verschil tussen de gemiddelden nul is. Als groep \(1\) een gemiddelde van \(10\) heeft en groep \(2\) een gemiddelde van \(10\), dan is \(10-10 = 0\). De \(t\)-waarde of de \(z\)-waarde zal in zo’n geval ook \(0\) zijn, want nul gedeeld door iets is altijd nul. Anders dan bij de \(z\)-waarde, staat nu onder de deelstreep in plaats van de populatievariantie een maat voor de variantie in beide groepen.
ANOVA heeft niet eenzelfde elegante, eenvoudige formule. In plaats van groepsgemiddelden van elkaar af te trekken worden de groepsgemiddelden als varianties behandeld. Waarom zo moeilijk doen?
De eenvoud achter de \(t\)-toetsformule maakt het vaak onnodig om alle onderliggende assumpties expliciet te benoemen, maar nu ANOVA ten tonele komt, kunnen we hier niet meer omheen. Het verschil tussen ANOVA en de \(t\)-toets is namelijk niet zozeer een verschil in formules, maar een verschil in wat de groepsgemiddelden voorstellen. De \(t\)-toets zoals hierboven besproken heeft als volledige naam de \(t\)-toets voor onafhankelijke steekproeven. Deze ingewikkelde naamgeving heeft een functie. Het drukt namelijk de volgende nulhypothese van een \(t\)-toets uit (24.3).
\[\begin{equation} H_0: \mu_1 = \mu_2 \tag{24.3} \end{equation}\]
In statistische wiskunde worden Griekse letters gebruikt om populatieparameters uit te drukken. Een \(t\)-toets vergelijkt dus niet zomaar twee gemiddelden, maar twee populatiegemiddelden. Een \(t\)-toets heeft eigenlijk een best ingewikkelde onderliggende logica. De \(\mu\) geeft aan dat bij een \(t\)-toets aangenomen wordt dat de populatiegemiddelden bekend zijn. De \(t\)-toets en de \(z\)-toets verschillen eigenlijk alleen in het feit dat bij de \(t\)-toets de populatievariantie alsnog niet bekend verondersteld wordt, maar de populatiegemiddelden wel. De \(t\)-toets toetst dus alleen nog of de twee steekproeven dezelfde populaties uitdrukken, of in ieder geval de gemiddelden daarvan.
ANOVA weerspiegelt een andere tak van groepsgemiddelden. Specifiek kan one-way ANOVA gezien worden als een toets van de homogeniteit van gemiddelden. Hiermee wordt bedoeld dat er, in tegenstelling tot bij de \(t\)-toets, bij ANOVA geen verschillende populaties vergeleken worden, maar dat iedere groep eigenlijk een subgroep is van een hogere-orde-factor. Bij ANOVA worden subgroepgemiddelden uit een populatie vergeleken met het globale populatiegemiddelde.
De vraag bij ANOVA is dus niet zozeer hoe je meer dan twee populatiegemiddelden kunt vergelijken, want het antwoord daarop is: doe gewoon meer \(t\)-toetsen. ANOVA toetst de homogeniteit van gemiddelden, met andere woorden of het mogelijk is om de subgroepgemiddelden van een populatie simpelweg met één populatiegemiddelde uit te drukken, of dat dit een te eenvoudig model is en dat een model waarin subgroepen verschillende gemiddelden hebben beter is.
Dit heeft als voordeel een eenvoudig te formuleren nulhypothese (24.4).
\[\begin{equation} H_0: \mu_1 = \mu_2 = \mu_3 = \ldots = \mu_k \tag{24.4} \end{equation}\]
Om de nuances achter het idee van een factor te begrijpen, wordt hier een voorbeeld gegeven.
Stel, een onderzoeker wil katten en honden vergelijken op hun verzorgingsgemak. Verzorgingsgemak is gemeten met een vragenlijst waarin mensen gevraagd werden katten en honden te beoordelen op allerlei criteria zoals kosten van voedsel, dierenarts, regelen oppas, zelfstandigheid van het dier enzovoort. Verzorgingsgemak wordt uitgedrukt in een totale score van \(1\) (geen enkel gemak) - \(10\) (heel veel gemak). Honden kregen gemiddeld een gemaksscore van \(4\). Katten kregen een gemiddelde gemaksscore van \(6\). Het totale gemiddelde voor alle dieren samen (honden én katten) was \(5\).
Hieronder volgen twee manieren om het ruwe verschil tussen honden en katten uit te drukken, de \(t\)-toets-zienswijze en de ANOVA-zienswijze. Voor het gemak en om nadruk te leggen op het conceptuele onderscheid wordt alleen naar het stukje ‘verschil’ gekeken en wordt het delen door de standaardfout (het standaardiseren) buiten beschouwing gelaten.
24.2.1 Verschil uitdrukken in een \(t\)-toets
Deze sectie kan kort zijn, want dit is hierboven al behandeld. Voor de volledigheid toch een korte herhaling. In de \(t\)-toets veronderstellen we dat honden en katten verschillende populaties betreffen. Dit betekent dat we het volgende aannemen:
- Honden zijn een populatie met gemiddelde \(\mu\) en een nog te schatten variantie \(S^2\).
- Katten zijn een populatie met gemiddelde \(\mu\) en een nog te schatten variantie \(S^2\).
- Beide populaties zijn normaal verdeeld.
De nulhypothese is (24.5)
\[\begin{equation} H_0: \mu_{honden} = \mu_{katten} \tag{24.5} \end{equation}\]
Omdat de onderzoeker verwacht dat honden en katten niet even gemakkelijk te verzorgen zijn, is de alternatieve hypothese (24.6)
\[\begin{equation} H_a: \mu_{honden} \neq \mu_{katten} \tag{24.6} \end{equation}\]
Toetstechnisch heeft de alternatieve hypothese geen waarde, want in de \(t\)-toets en in ANOVA wordt tegen de nulhypothese getoetst. De laatste aanname bij een \(t\)-toets is daarom tegenintuïtief:
Honden en katten zijn twee populaties die alleen verschillen in hun modus (gemiddelde).
Voor de \(t\)-toets wordt het ruwe verschil, de variabiliteit, berekend als (24.7)
\[\begin{equation} 4 - 6 = -2 \tag{24.7} \end{equation}\]
Katten zijn volgens de \(t\)-toets dus een populatie die \(2\) punten meer verzorgingsgemak bezitten dan honden.
24.2.2 Verschil uitdrukken in ANOVA
Hoewel we uiteindelijk tot dezelfde conclusie gaan komen als bij de \(t\)-toets (sorry, spoiler alert), zien we de omweg die ANOVA neemt en leren we waarom de ANOVA-formule zo afwijkt van die van de \(t\)-toets.
In ANOVA veronderstellen we dat katten en honden beiden subgroepen zijn van de hogere categorie of factor ‘dier’. Dit betekent dat we het volgende aannemen:
- Dieren zijn een populatie met gemiddelde \(\mu\) en een nog te schatten variantie \(S^2\).
- Katten en honden zijn ieder een subgroep uit de populatie dieren met te schatten gemiddelde \(\bar{X}\) en een nog te schatten variantie \(S^2\).
- De populatie dieren is normaal verdeeld.
De nulhypothese is niet veranderd (24.8)
\[\begin{equation} H_0: \mu_{honden} = \mu_{katten} \tag{24.8} \end{equation}\]
Het verschil ligt in het berekenen van de totale variabiliteit. Omdat honden en katten niet horizontaal met elkaar vergeleken worden, maar eigenlijk ieder met hun overstijgende factor ‘dieren’, is deze vergelijking verticaal. De aanname is dat, als het algemene gemiddelde van alle dieren het beste model is, dat alle subgroepen – hier dus katten en honden – hetzelfde gemiddelde hebben als het algemeen gemiddelde. Vervolgens wordt beredeneerd, als katten en honden beiden het algemeen gemiddelde als subgroepgemiddelde hebben, dan hebben ze dus hetzelfde gemiddelde. Formuletechnisch ziet de berekening van de totale variabiliteit (het deel boven de deelstreep) er dus anders uit dan bij de \(t\)-toets (24.9).
\[\begin{equation} (\bar{X}_{katten} - \mu) + (\bar{X}_{honden} - \mu) \tag{24.9} \end{equation}\]
Maar! Merk op dat we deze situatie, waarin afwijkingen berekend worden, kennen van het berekenen van de standaarddeviatie. Soms valt een afwijking iets boven het gemiddelde uit en soms eronder, maar in totaal tellen de afwijkingen van een gemiddelde altijd op tot nul. Hier moet dus een oplossing voor gevonden worden en in ANOVA is gekozen voor een variantiebenadering. Dit betekent dat we de afwijkingen van de subgroepgemiddelden tot het totale gemiddelde eerst nog kwadrateren (24.10).
\[\begin{equation} (\bar{X}_{honden} - \mu)^2 + (\bar{X}_{katten} - \mu)^2 \tag{24.10} \end{equation}\]
Als we de getallen voor de honden en katten invullen, ziet dat er als volgt uit (24.11).
\[\begin{equation} (4 - 5)^2 + (6 - 5)^2 = (-1)^2 + (1)^2 = 1 + 1 = 2 \tag{24.11} \end{equation}\]
In ANOVA wordt het verschil tussen subgroepen dus uitgedrukt als een optelling van gekwadrateerde groepsafwijkingen van het algemeen populatiegemiddelde. Daarom wordt de variabiliteit in ANOVA de kwadratensom genoemd, in het Engels bekend als de sum of squares. Deze term zal nog veelvuldig terugkomen.
Merk op dat bij de \(t\)-toets het verschil in gemaksscore tussen honden en katten een negatief getal was, waardoor we aan het verschil meteen konden zien dat honden een lagere gemaksscore hadden dan katten. Bij een kwadratensom is een negatieve somscore onmogelijk.
De variantiebenadering heeft vele voordelen, maar ook een belangrijk nadeel. Door alle groepsgemiddelden als facetten van een hogere-orde-factor te beschouwen, worden alle gemiddelden, of dat er nu twee of twintig zijn, als één set geëvalueerd. Verfijnde verschillen tussen meer dan twee groepen onderling – bijvoorbeeld of muizen gemakkelijker in de verzorging zijn dan honden, maar even gemakkelijk als katten – is niet mogelijk in deze benadering. Omdat ANOVA alleen over de set als geheel een uitspraak doet, wordt ANOVA een omnibustoets genoemd. Als we specifieke groepsverschillen willen toetsen, komen we weer terug in het paradigma van de \(t\)-toetsen, dat iedere groep een eigen populatie is.
24.2.3 De \(F\)-waarde als ratio
De bekende hypothesetoetsen, zoals de \(z\)-toets en de \(t\)-toetsen, hebben namen die passen bij hun toetsstatistiek, zoals de \(z\)-waarde en de \(t\)-waarde. Hoewel ANOVA met haar \(F\)-waarde hier een uitzondering op lijkt, is niets minder waar. De \(F\)-waarde ontleent haar naam aan de bekende statisticus Fisher. De volledige naam van de \(F\)-verdeling waar een \(F\)-waarde uit berekend kan worden, is de Fisher-Snedecor-verdeling. Het was niet Fisher die ANOVA bedacht, maar Snedecor had een aantal problemen opgelost die aan de \(F\)-toets van Fisher kleefden. Om Fisher te eren gaf hij de exacte \(F\)-test mede de naam van Fisher.
De \(F\)-waarde in formulevorm kan met woorden als volgt worden geschreven:
\[\begin{equation} F = \frac{\text{variantie van de groepsgemiddelden}}{\text{gemiddelde van de varianties binnen groepen}} \tag{24.12} \end{equation}\]
De \(F\)-waarden zijn gebaseerd op de verhouding van varianties. En varianties worden berekend op basis van het optellen van gekwadrateerde afwijkingen van gemiddelden. Dit worden kwadraatsommen genoemd of in het Engels sum of squares (SS). Wanneer je de SS deelt door het aantal vrijheidsgraden (degrees of freedom, \(df\), zie de paragraaf Vrijheidsgraden in het hoofdstuk Beschrijvingsmaten voor een toelichting) dat bij die term hoort, dan krijg je de zogenaamde mean squares (MS).
Bovenstaande formule vertaalt zich met behulp van de MS in een meer wiskundige formule als volgt:
\[\begin{equation} F = \frac{MS_b}{MS_w} \tag{24.13} \end{equation}\]
De \(MS_b\) is de variantie tussen (between) de groepen, en \(MS_w\) de variantie binnen (within) de groepen. De vrijheidsgraden van de \(MS_b\) is het aantal groepen (k) - 1 en van de \(MS_w\) N-k, waarbij N de steekproefgrootte is, oftewel het totaal aantal personen.
De \(F\)-waarde staat dus centraal in ANOVA, maar het is misschien niet meteen duidelijk hoe je een \(F\)-waarde moet interpreteren. Bij een \(z\)-waarde is de betekenis redelijk intuïtief: het aantal standaarddeviaties dat een observatie van een nulhypothetisch gemiddelde afwijkt. De \(F\)-waarde bij ANOVA heeft gelukkig ook een intuïtieve betekenis. Een \(F\)-waarde kan gezien worden als een signaal-ruisverhouding (Engels: signal-to-noise ratio).
ANOVA toetst verschillen tussen groepsgemiddelden door twee soorten varianties tegen elkaar uit te zetten. Aan de ene kant wordt vastgesteld hoeveel groepsgemiddelden, bij elkaar opgeteld (en gekwadrateerd), afwijken van het algemene populatiegemiddelde. Dit is het model dat een onderzoeker voor ogen heeft, namelijk dat een populatie het beste samengevat wordt als dat per subgroep gebeurt. De omvang van dit totale verschil is de tussengroepenvariantie en dit is het signaal dat de onderzoeker wil oppikken.
Aan de andere kant analyseert ANOVA de verschillen binnen iedere groep. In iedere subgroep wordt niet door iedereen precies het gemiddelde gescoord, maar is er ongetwijfeld individuele variatie. Deze binnengroepenvariantie is niet deel van het model, maar eigenlijk onverklaarde individuele afwijking van groepsgemiddelden. De omvang van de binnengroepenvariantie kan dus als ruis worden gezien.
Om de vraag te beantwoorden hoe scherp het signaal is, is er een indicatie nodig voor de hoeveelheid signaal ten opzichte van de ruis. Door het signaal te delen door de ruis krijgen we een verhouding die groter is dan \(1\) zodra er meer signaal is dan ruis, en kleiner dan \(1\) is als er meer ruis is dan signaal. De \(F\)-waarde is dus de tussengroepenvariantie (signaal) gedeeld door de binnengroepenvariantie (ruis).
Net als bij alle significantietoetsen is dan alleen nog de vraag: hoe groot moet het verschil zijn om als ‘groot’ bestempeld te worden. Hoeveel meer signaal dan ruis nodig is, hangt af van het aantal groepen dat vergeleken wordt en van het aantal observaties in totaal. Dit kan nogal variëren, maar stel dat er twee groepen vergeleken worden bij een steekproefgrootte van \(30\) en een alfa van \(.05\), dan is de \(F\)-waarde significant als er zo’n vier keer meer tussengroepenvariantie is dan binnengroepenvariantie (\(F = 4.17\)). Als er tien groepen vergeleken worden, moet het signaal ruim twee keer zo groot zijn dan de ruis (\(F = 2.21\)).
Om de samenhang tussen de \(F\)-waarde en significantie te illustreren, wordt in Figuur 24.1 getoond hoe de tussengroepenvariantie (verschillen tussen groepsgemiddelden) en de binnengroepenvariantie (verschillen binnen groepen) samen de duidelijkheid van een patroon bepalen. In alle drie de figuren is de variantie binnen de groepen constant en varieert alleen het verschil tussen de groepen.
In de meest linkse figuur is het moeilijk om te zien waar een groep begint en de andere eindigt. De gemiddelden liggen dicht bij elkaar en hoewel de binnengroepenvariantie niet heel groot is, is deze in verhouding tot de verschillen tussen de groepen groot genoeg om de drie groepen vrijwel samen te laten klonteren. In de middelste en vooral in de rechterfiguur wordt duidelijk dat zodra er meer variantie tussen de groepen is, er zich een veel duidelijker patroon aftekent. Het signaal is nu glashelder en er zijn drie hele duidelijke groepen zichtbaar, ondanks enige overlap in de staarten.
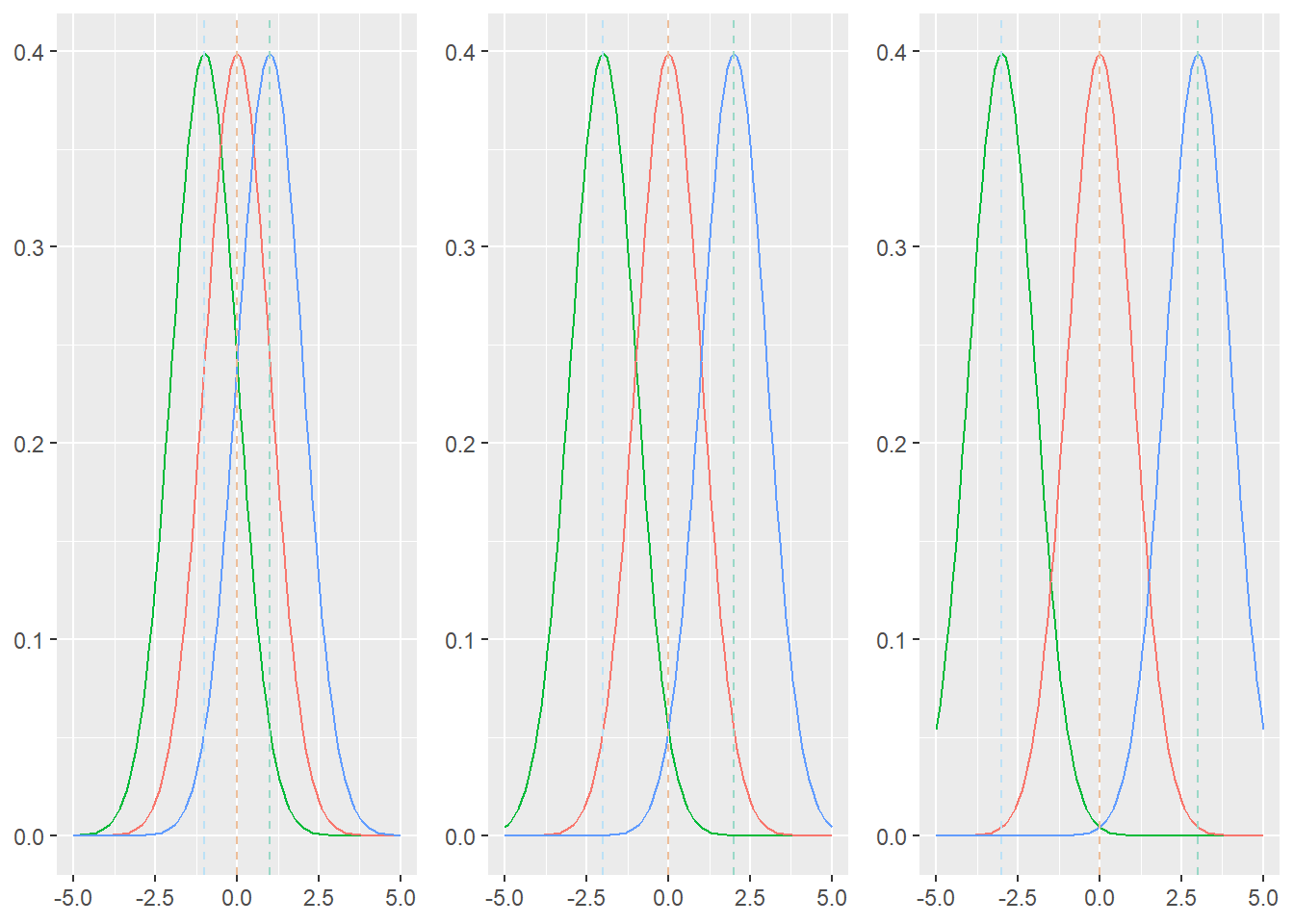
Figuur 24.1: Verdelingen met in elke figuur dezelfde varianties (binnen groepen), maar verschillende gemiddelden (tussen groepen)
Iets vergelijkbaars is te zien wanneer de gemiddelden constant blijven en alleen de binnengroepenvariantie, dus de ruis, varieert. In Figuur 24.2 is er links heel weinig ruis, waardoor de al aanwezige verschillen tussen de groepen, het signaal, onmiskenbaar helder wordt: de drie groepen zijn tot ver in de staarten duidelijk van elkaar te onderscheiden. Dit signaal raakt snel verloren in de figuren ernaast, waarbij in de laatste figuur het signaal bijna volledig overschaduwd wordt door de ruis. Ondanks de toch zo duidelijke verschillen tussen de groepsgemiddelden, klontert alles samen tot een homogene massa en is het in de praktijk moeilijk te bepalen of iemand met een gegeven waarde uit groep A, B of C komt.
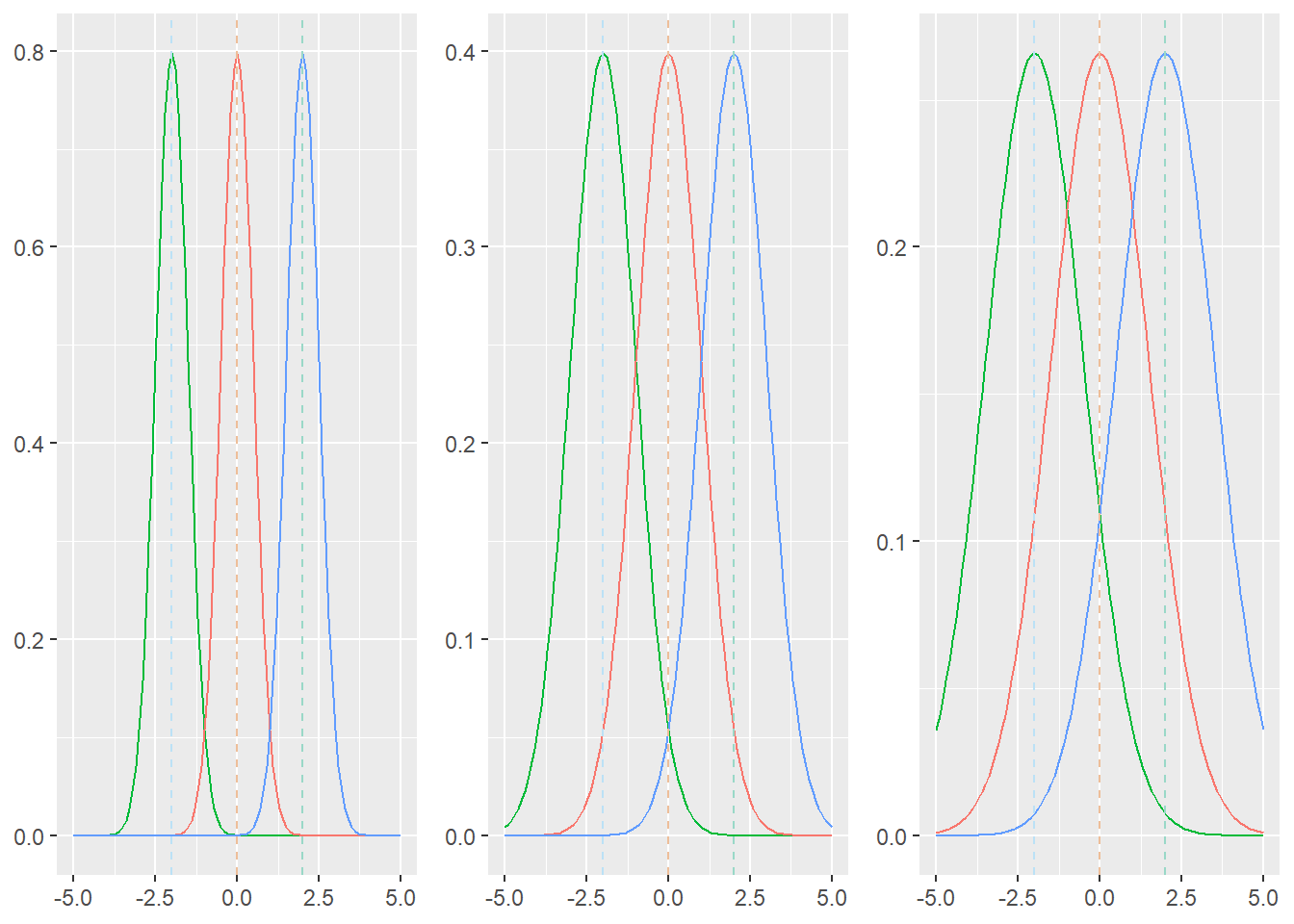
Figuur 24.2: Verdelingen met in elke figuur dezelfde gemiddelden (tussen groepen), maar verschillende varianties (binnen groepen)
De \(F\)-waarde is dus een verhouding tussen modelvariantie (signaal) en residuele variantie (ruis) die uitdrukt hoeveel meer modelvariantie dan residuele variantie er is. Als dit getal groter is dan \(1\), is er meer modelvariantie dan residuele variantie. Hoe groter de \(F\)-waarde, des te duidelijker is er een signaal waarneembaar.
24.3 Aannamen bij ANOVA
Hieronder worden kort de aannamen bij het uitvoeren van een ANOVA opgesomd.
De residuen zijn normaal verdeeld. Als de residuen enigszins normaal verdeeld zijn, kun je ervan uitgaan dat de optimale oplossing voor het model gevonden is.
Er is sprake van homogeniteit van de varianties. Hiermee wordt bedoeld dat de varianties in de verschillende groepen (ongeveer) gelijk zijn. Als de varianties ongelijk zijn, is het voor de nulhypothese-significantietoetsing en voor de betrouwbaarheidsintervallen belangrijk dat er een aangepaste toets gebruikt wordt die rekening houdt met deze ongelijke varianties, zoals de Welch’s \(F\) (zie hieronder).
De scores op de afhankelijke variabele zijn onafhankelijk van elkaar.
Er zijn geen verstorende uitbijters in de data. Door een uitbijter kunnen de gemiddelden en varianties sterk beïnvloed worden. Inspecteer daarom eerst goed de data op uitbijters en mogelijke andere ‘vreemde’ waarden.
24.3.1 Welch’s \(F\)
Wanneer de aanname van homogeniteit van varianties geschonden wordt, dus als de varianties ongelijk zijn, is het beter om een aangepaste toets te gebruiken die corrigeert voor de verschillen in varianties. Een van deze alternatieven is de Welch’s \(F\). Eigenlijk kun je altijd beter de Welch’s \(F\) gebruiken. Deze toets houdt automatisch rekening met ongelijke varianties en als de varianties toch gelijk blijken te zijn, is het resultaat vergelijkbaar met de standaard \(F\)-toets.
Om te controleren of aan de aanname van homogeniteit van varianties voldaan wordt, kun je gebruik maken van Leven’s toets. Deze wordt besproken in het hoofdstuk t-testen en Cohen’s d.
24.4 Effectmaten bij ANOVA
Voor variantieanalyse bestaan verschillende effectmaten die de effectgrootte aangeven. Het gaat hierbij dus om de grootte van het effect van een experimentele manipulatie. Een hoge waarde geeft aan dat de manipulatie effect heeft gehad op de afhankelijke variabele. Het idee achter een maat voor effectgrootte is dat de interpretatie van deze maat onafhankelijk is van het soort data of experiment dat is uitgevoerd.
Allereerst is er de R-kwadraat (\(R^2\)), die de verhouding aangeeft tussen de kwadratensom tussen groepen en de totale kwadratensom (24.14).
\[\begin{equation} R^2 = \frac{SS_M}{SS_T} \tag{24.14} \end{equation}\]
\(SS_M\) staat hier voor de sum of squares van het effect in het model (de variatie tussen de groepen) en \(SS_T\) voor de totale variatie (sum of squares).
\(R^2\) wordt bij ANOVA meestal aangeduid met de Griekse letter \(\eta^2\), uitgesproken als eta-kwadraat.
Aangezien \(\eta^2\) gebaseerd is op de steekproef en daardoor onzuiver is, wordt tegenwoordig een iets aangepaste effectmaat gebruikt, aangeduid met de Griekse letter \(\omega^2\), omega-kwadraat. De \(\omega^2\) is een zuivere schatting van het effect in de populatie (24.15).
\[\begin{equation} \omega^2 = \frac{SS_M - (df_M) MS_R}{ SS_T + MS_R } \tag{24.15} \end{equation}\]
De \(df_M\) staat voor het bij de \(SS_M\) behorende aantal vrijheidsgraden. \(MS_R\) staat voor de ‘residuele’ of ‘error’ mean squares (dus de variantie binnen de groepen). Soms kan ook de volgende formule worden gebruikt (24.16):
\[\begin{equation} \omega^2 = \frac{ F - 1 }{ F + \frac{ (df_\text{error} + 1)}{ df_\text{effect} } } \tag{24.16} \end{equation}\]
Hierbij is \(df_\text{error}\) het aantal vrijheidsgraden van de errorterm, in dit geval de binnengroepenvariantie, en \(df_\text{effect}\) het aantal vrijheidsgraden van de verklaarde variantie door de onafhankelijke variabele, in dit geval de tussengroepenvariantie.
Deze alternatieve formule is handig als je de sterkte van een verband wilt berekenen uit de gegevens van een wetenschappelijk artikel. De sum of squares wordt namelijk zelden gerapporteerd, maar de \(F\)-waarde met bijbehorende vrijheidsgraden bijna altijd wel.
Soms worden de waarden van \(0.01\), \(0.06\) en \(0.14\) voor \(\omega^2\) gezien als respectievelijk een zwak, middelmatig en een sterk effect. Dit is echter een hele grove vuistregel, want een effectgrootte moet altijd geïnterpreteerd worden in de context van het desbetreffende vakgebied.
24.5 Specifieke groepsverschillen toetsen: contrasten versus post-hoc
De \(F\)-waarde is een omnibustoets, wat betekent dat een \(F\)-waarde alleen een uitspraak doet over een factor in totaliteit. Een significante \(F\)-waarde betekent daarom nooit meer dan dat minstens één groep van minstens één andere groep afwijkt. Een significante \(F\)-waarde geeft aan dat een model waarin alle groepsgemiddelden gelijk zijn, of specifieker waarin alle groepsgemiddelden gelijk zijn aan het algemeen gemiddelde, een model is wat verworpen mag worden.
De vraag die dan ontstaat, is welke groepen dan van elkaar verschillen. Dit vereist dat het ANOVA-raamwerk verlaten moet worden en er een uitstapje gemaakt moet worden naar het \(t\)-toets-raamwerk. Met andere woorden, om specifieke groepsvergelijkingen te toetsen moeten alsnog \(t\)-toetsen worden gedaan.
Het is van belang om te realiseren dat iedere extra hypothesetoets een toename van de kans op een type 1-fout met zich meebrengt (zie paragraaf Significantie van het hoofdstuk Nulhypothese-significantietoetsing). Om deze reden worden modellen geprefereerd die het minste aantal toetsen vereisen. Dit heeft tot gevolg dat er twee benaderingen zijn om specifieke vergelijkingen te toetsen na een ANOVA. De zuinigste van deze twee opties, de contrasten, geniet de voorkeur.
Als onderzoekers vooraf bepaald hebben welke specifieke vergelijkingen ze willen toetsen, wordt van contrasten gesproken, ook wel ‘a-priori-’ of ‘geplande’ contrasten genoemd. Het alternatief is post-hoc-testen, wat een chique manier is om te zeggen ‘Ik ga alsnog alle mogelijke paarsgewijze vergelijkingen toetsen’.
24.5.1 Contrasten: paarsgewijze vergelijkingen van tevoren bedenken
Bij het opstellen van een hypothese is in veel gevallen al een idee aanwezig over welke vergelijkingen noodzakelijk of zinvol zijn, en welke vergelijkingen weinig interessant zijn. Een onderzoeker die bijvoorbeeld een nieuw medicijn wil onderzoeken, kan een factor conditie hebben met drie niveaus: (1) placebo, (2) bestaand medicijn en (3) experimenteel medicijn.
De onderzoeker heeft eigenlijk slechts twee vragen te beantwoorden: (a) scoren de deelnemers die een echt medicijn krijgen beter dan de deelnemers uit de placebogroep, en (b) werkt het experimentele medicijn beter dan het bestaande medicijn? In plaats van drie paarsgewijze vergelijkingen te doen (placebo-bestaand, placebo-experimenteel, bestaand-experimenteel), waarbij de kans op een type-1 fout \(p = .95^3 = .86\) is, zijn er eigenlijk maar twee vergelijkingen nodig, waarbij de kans op type-1 fout \(p = .95^2 = .90\) is.
Er zijn veel soorten contrasten denkbaar. Wat alle contrasten met elkaar gemeen hebben, is dat een set van groepen paarsgewijs vergeleken wordt. In feite wordt steeds een \(t\)-toets geforceerd. Het voorbeeld van de onderzoeker die een medicijn wil evalueren, representeert twee manieren om van een contrast tot een \(t\)-toets te komen. In de vergelijking tussen het bestaande en het experimentele medicijn worden twee groepen vergeleken en deze situatie is nagenoeg identiek aan die van de onafhankelijke \(t\)-toets. In de vergelijking tussen placebo en medicijn moet er eerst nog een wiskundige bewerking plaatsvinden om tot een \(t\)-toets-situatie, het vergelijken van twee gemiddelden, te komen.
Contrasttoetsen kunnen het beste voorgesteld worden als een klassieke weegschaal met twee schaaltjes en een wijzer in het midden. Dit is het type weegschaal waar het te wegen object aan een kant wordt gelegd en een contragewicht aan de andere kant totdat beide kanten van de weegschaal in balans zijn. In een contrasttoets worden paarsgewijze vergelijkingen gemaakt door groepen die niet in de vergelijking worden opgenomen een gewicht van ‘nul’ te geven, en de groepen die tegen elkaar vergeleken worden even zwaar te maken.
Als placebo vergeleken wordt met ‘medicijn’ is het in eerste instantie een vergelijking uit balans, omdat placebo vergeleken wordt met twee groepen, namelijk het bestaande en het experimentele medicijn. Een contrasttoets lost dit op door het gewicht van de twee medicijngroepen te balanceren door de placebogroep even zwaar te maken, in dit geval door het gemiddelde van de placebo twee keer zoveel gewicht te geven in de analyse. De gewogen som van alle gemiddelden wordt uitdrukt als de Griekse letter psi (\(\psi\)).
Stel dat het medicijn in ons voorbeeld moet leiden tot meer geluk. De onderzoeker moet de weegschaal op nul zien te krijgen bij ieder contrast. De precieze getallen bij het wegen zijn niet belangrijk, zolang beide kanten van de weegschaal samen nul zijn. De verwachting is dat placebo een slechtere werking heeft dan de medicijnen en daarom krijgt placebo in het eerste contrast een negatief gewicht. De medicijnen moeten beter werken dan placebo en krijgen daarom een positief gewicht. De twee medicijngroepen samen moeten even zwaar zijn als de placebogroep alleen. De onderzoeker weegt ieder medicijn voor de helft, zodat \(0.5 + 0.5 = 1\) opweegt tegen \(-1\) van de placebogroep.
In het tweede contrast is de onderzoeker alleen geïnteresseerd in het verschil tussen de twee medicijnen. Placebo krijgt daarom in het tweede contrast een gewicht van nul. Het bestaande medicijn zou tot minder geluk moeten leiden dan het experimentele medicijn, dus krijgt het bestaande medicijn een negatief gewicht tegenover het positieve gewicht voor het experimentele medicijn. Omdat hier twee groepen met elkaar vergeleken worden, is de weegschaal in balans als iedere groep met een volledig gewicht meetelt. Er wordt dus een weging van \(1\) aan iedere groep toegekend. De contrasten zijn te zien in Tabel 24.1.
| Contrast | Placebo | Bestaand medicijn | Experimenteel medicijn |
|---|---|---|---|
| 1 | -1 | 0.5 | 0.5 |
| 2 | 0 | -1 | 1 |
Dit voorbeeld kan ook in getallen gegeven worden. Hoewel de meeste software tegenwoordig de sum of squares gebruikt om contrasten met een \(F\)-toets te berekenen, is een \(t\)-toets-benadering conceptueel duidelijker (Myers, Well, & Lorch, 2010). In feite wordt namelijk bij een contrast een \(t\)-toets uitgevoerd, maar dan met een twist.
Allereerst worden gewogen gemiddelden van elkaar afgetrokken boven de deelstreep en de standaardfout wordt gebaseerd op de mean square van de residuen/error uit ANOVA. Voor het rekenvoorbeeld moet meer informatie aanwezig zijn.
In Tabel 24.2 wordt het gemiddelde geluk na afloop van het experiment gegeven. De mean square van de residuals (MSR) is in dit voorbeeld \(1.833\).
| Groep | M | N | Contrast 1 | Contrast 2 |
|---|---|---|---|---|
| Placebo | 6 | 20 | -1 | 0 |
| Bestaand medicijn | 9 | 20 | 0.5 | -1 |
| Experimenteel medicijn | 6 | 20 | 0.5 | 1 |
De gewogen som van de gemiddelden wordt als volgt berekend.
\[\begin{equation} \widehat{\psi} = \sum{w_{j}\overline{Y}_{j}} \tag{24.17} \end{equation}\]
Deze formule stelt dat voor ieder subgroepgemiddelde (\(\overline{Y}_{j}\)) er een gewicht wordt toegekend (\(w_{j}\)). Voor contrast \(1\) is de gewogen som van alle gemiddelden.
\[\begin{equation} \psi = -1(6) + 0.5(9) + 0.5(6) = -6 + 4.5 + 3 \approx 1.5 \tag{24.18} \end{equation}\]
Het ruwe gewogen verschil tussen placebo en de medicijngroepen is \(1.5\) gelukspunt. Om te beoordelen of dit naar verhouding een noemenswaardig verschil is, moet nog door de gewogen standaardfout gedeeld worden.
De formule van de standaarddeviatie voor het contrast is:
\[\begin{equation} s_{\widehat{\psi}} = \sqrt{MSR\sum{\frac{w_{j}^{2}}{n_{j}}}} \tag{24.19} \end{equation}\]
Deze formule berekend de standaarddeviatie door de wortel te nemen van de residuele ANOVA-variantie, die eerst nog (gekwadrateerd) gewogen is naar het contrast en de steekproefgrootte per groep. Dit laatste is noodzakelijk, omdat de residuele variantie afhankelijk is van de groepsgrootte. Hoe groter de steekproef, hoe groter de variantie. Het eerste contrast heeft een standaarddeviatie van:
\[\begin{equation} s_{\widehat{\psi}} = \sqrt{1.833\left[\frac{-1}{20}^2 + \frac{0.5}{20}^2 + \frac{0.5}{20}^2 \right]} \tag{24.20} \end{equation}\]
\[\begin{equation} s_{\widehat{\psi}} = \sqrt{1.833\left[\frac{1.5}{20}\right]} = \sqrt{0.1375} \approx 0.37 \tag{24.21} \end{equation}\]
De significantietoets wordt vervolgens met de \(t\)-toets-formule berekend, het ruwe verschil gedeeld door de meetfout:
\[\begin{equation} t_{contrast1} = \frac{\widehat{\psi}}{s_{\widehat{\psi}}} \tag{24.22} \end{equation}\]
\[\begin{equation} t_{contrast1} = \frac{1.5}{0.37} \approx 4.05 \tag{24.23} \end{equation}\]
Het aantal vrijheidsgraden (\(df\)) is de totale \(N\) minus het aantal groepen, ook als deze een weging van nul hebben. Dus in dit geval is \(df = N - k = 3(20) - 3 = 60 - 3 = 57\). Bij dit aantal vrijheidsgraden zou de \(t\)-waarde significant zijn vanaf \(t* = 2.00\). Omdat \(t = 4.05\) groter is dan de kritieke \(t\)-waarde (\(t*\)), is het verschil tussen de placebogroep en de medicijngroepen significant. De medicijngroepen hebben gemiddeld een hogere geluksscore dan de placebogroep.
Voor contrast \(2\), het vergelijken van het bestaande medicijn met het experimentele medicijn, ziet de berekening voor de gewogen som van de gemiddelden er als volgt uit, rekening houdend met dat de placebogroep niet vergeleken wordt en dus een weging van nul krijgt.
\[\begin{equation} \widehat{\psi} = \sum{w_{j}\overline{Y}_{j}} = 0(6) + -1(9) + 1(6) = 0 + -9 + 6 = -3 \tag{24.24} \end{equation}\]
De standaarddeviatie is uiteindelijk, ondanks de andere gewichten, precies hetzelfde als bij contrast \(1\).
\[\begin{equation}s_{\widehat{\psi}} = \sqrt{MSR\sum{\frac{w_{j}^{2}}{n_{j}}}} = \sqrt{1.833\left[\frac{0}{20}^2 + \frac{-1}{20}^2 + \frac{1}{20}^2 \right]} = \sqrt{1.833\left[\frac{2}{20}\right]} = \sqrt{0.1833} \approx 0.43 \tag{24.25} \end{equation}\]
Contrast \(2\) heeft als \(t\)-waarde:
\[\begin{equation}t_{contrast2} = \frac{\widehat{\psi}}{s_{\widehat{\psi}}} = \frac{-3}{0.43} \approx -10.47 \tag{24.26} \end{equation}\]
Bij \(df = 57\) is het geen verassing dat dit contrast significant is. Maar, vergeet niet dat de onderzoeker de verwachting had dat het experimentele medicijn tot meer geluk zou leiden dan het reeds bestaande medicijn. In dit voorbeeld was dit niet het geval. Het ruwe verschil van \(3\) gelukspunten was in het voordeel van het bestaande medicijn. Hoewel dit contrast dus statistisch significant is, gaat de onderzoeker toch met zwaar gemoed huiswaarts na een lange dag contrasten uitrekenen.
24.5.2 Post-hoc: achteraf alsnog alles vergelijken, maar voorzichtiger
Er zijn situaties waar contrasten opstellen niet mogelijk is, of waarin de onderzoeker elke groep met elkaar wil vergelijken. In zo’n geval kan een onderzoeker weinig anders doen dan wat in de praktijk neerkomt op alsnog alle \(t\)-toetsen uitvoeren die met ANOVA in eerste instantie vermeden werden. Om type 1-foutinflatie tegen te gaan, wordt er bij een post-hoc-toetsprocedure ervoor gekozen om de \(p\)-waarde te verhogen of om tegen een strengere alfa te toetsen. Hiermee wordt de kans op een type 2-fout wellicht groter, maar dit is nodig om de toegenomen kans op een type 1-fout terug in balans te krijgen.
Deze aanpassingen op de \(p\)-waarde gebeuren niet hapsnap: het is niet te bedoeling om te overcompenseren en meer type 2-fout te verliezen dan noodzakelijk. Er zijn veel manieren om te corrigeren voor het aantal paarsgewijze vergelijkingen. Een zo compleet mogelijke lijst gaat aan het doel (en de leesbaarheid) van dit document voorbij. Enkele van de meest gebruikte methoden worden hier besproken.
Een kort woord vooraf: van oorsprong werd bij sommige correcties gesproken over een correctie op de alfa. Er werd een strengere alfa gebruikt om tegen te toetsen. Dit stamt nog uit de tijd dat \(p\)-waarden niet berekend werden, maar opgezocht in een tabel. Analyseprogramma’s hebben geen moeite met het exact berekenen van \(p\)-waarden. Correcties in analysesoftware gebeurt daarom door de correctie uit te voeren op de \(p\)-waarde. Zo wordt bijvoorbeeld de \(p\)-waarde vermenigvuldigd met, in plaats van de alfa gedeeld door, het aantal paarsgewijze vergelijkingen.
Om deze reden kan het zijn dat een post-hoc-analyse \(p\)-waarden van \(1.00\) laat zien. Dit is geen fout, maar een gevolg van de post-hoc-correctie. De bovengrens van \(p\)-waarden is \(1.00\), dus zodra de vermenigvuldiging een getal groter dan \(1.00\) oplevert, zet de software de \(p\)-waarde op \(1.00\). Een tabel vol met \(p\)-waarden van \(1.00\) is dus geen rekenfout, maar een resultaat van vermenigvuldigde \(p\)-waarden die de bovengrens bereikt hebben of overstegen zijn.
24.5.2.1 Least squared difference (LSD)
Least squared difference (LSD) is in feite geen correctie, maar een manier om statistische software te vragen om alle \(t\)-toetsen, ongecorrigeerd, uit te voeren op alle paarsgewijze vergelijkingen.
Een ezelsbruggetje: gebruik nooit LSD. Dit ezelsbruggetje is er alleen ter lering ende vermaak. Laat het gebruik van LSD als correctiefactor zeker niet afhangen van je houding tegenover andere bestaansvormen van LSD. Als je maar geen gebruikmaakt van statistische LSD.
24.5.2.2 Bonferonni-correctie
De makkelijkste (in termen van conceptuele en rekenkundige eenvoud), maar tegelijkertijd ook de strengste correctiefactor is de Bonferonni-correctie. In de meeste statistiekboeken wordt de Bonferonni-correctie uitgelegd als het delen van de gewenste alfa (vaak \(.05\)) door het aantal paarsgewijze vergelijkingen. Bij drie paarsgewijze vergelijkingen en een gewenste alfa van \(.05\) wordt de Bonferonni-gecorrigeerde alfa: \(\alpha_{Bonferonni} = .05 / 3 \approx . 0167\). Als er post-hoc vier groepen vergeleken worden, zijn er zes paarsgewijze vergelijkingen met een Bonferonni-gecorrigeerde alfa van \(\alpha_{Bonferonni} = .05 / 6 \approx 0.0083\).
In statistische software wordt een wiskundig equivalente correctie uitgevoerd. De geobserveerde \(p\)-waarde wordt hier vermenigvuldigd met het aantal paarsgewijze vergelijkingen. Stel dat een van de paarsgewijze vergelijkingen een \(p\)-waarde had van \(.016\). Deze zou bij een alfa van \(.05\) significant zijn. Als deze \(p\)-waarde er een was uit drie paarsgewijze vergelijkingen, zou deze \(p\)-waarde na Bonferonni-correctie \(p = 3(.016) = .048\) zijn. Bij een alfa van \(.05\) is deze Bonferonni-gecorrigeerde \(p\)-waarde nog steeds significant.
Bonferonni is, zoals eerder genoemd, de strengste correctiefactor. Belangrijk om te weten is dat de Bonferonni-correctie als assumptie heeft dat het aantal observaties per groep gelijk is en dat de variantie tussen de groepen gelijk is.
24.5.2.3 Tukey-Kramer (honestly significant difference)-test
De Tukey-Kramer-methode, ook bekend als de Tukey-HSD (honestly significant difference)-test, is een veelgebruikte post-hoc-test voor wanneer het aantal observaties per groep ongelijk is, maar de varianties tussen de groepen wel gelijk zijn.
De Tukey-HSD-test is geen post-hoc-correctie op de alfa of \(p\)-waarde, althans het is geen directe aanpassing. Het betreft een aangepaste \(t\)-toets waarbinnen voor type 1-foutinflatie gecorrigeerd wordt. Op het eerste gezicht lijkt de Tukey-Kramer-methode exact op een \(t\)-toets.
\[\begin{equation} q_{s} = \frac{Y_{A} - Y_{B}}{SE} \tag{24.27} \end{equation}\]
Het addertje onder het gras bevindt zich hier boven het gras, namelijk boven de deelstreep. \(Y_A\) is de hoogste van twee vergeleken gemiddelden en \(Y_B\) de laagste van twee vergeleken gemiddelden. Het is dit kleine verschil met hoe de ‘normale’ \(t\)-toets berekend wordt, waarin eigenlijk een grote afwijking van de \(t\)-toets zit verstopt. Doordat het minimum (de laagste waarde) van het maximum (de hoogste waarde) wordt afgetrokken, is de verdeling niet meer een gewone student’s \(t\)-verdeling, maar een studentized \(t\)-verdeling.
De details van de gevolgen hiervan worden je bespaard. Het volstaat om te weten dat deze ogenschijnlijk kleine aanpassing aan de formule van de \(t\)-toets nadrukkelijke gevolgen heeft voor de berekening van de \(p\)-waarde behorende bij de \(t\)-waarde die uit de Tukey-HSD-test rolt. Doordat de studentized \(t\)-verdeling een conservatievere \(p\)-waarde oplevert dan de ‘gewone’ student’s \(t\)-verdeling, doet de berekening van een studentized \(p\)-waarde dienst als correctie op de \(p\)-waarde voor meerdere paarsgewijze vergelijkingen.
24.5.2.4 Dunnett’s \(t\)-test
De Dunnett’s \(t\)-test is kort-door-de-bocht gesteld een contrasttoets verstopt tussen de post-hoc-testen. De Dunnett’s \(t\)-test is bedoeld om een set van experimentele condities te toetsen tegen een controleconditie. Hoe je in de analyse aangeeft welke conditie de controleconditie is, is afhankelijk van de gebruikte software. Voor iedere experimentele conditie wordt een paarsgewijze vergelijking gemaakt met de controleconditie. De Dunnett’s \(t\)-test heeft als assumptie dat varianties tussen de vergeleken groepen aan elkaar gelijk zijn.
24.5.2.5 Games-Howell-test
De Games-Howell-test is een voorbeeld van een post-hoc-test waarin ongelijke groepsgroottes en ongelijke varianties tussen groepen verondersteld worden. Net als de Tukey-HSD-test gebruikt de Games-Howell-test een studentized \(t\)-verdeling, waardoor een conservatievere \(p\)-waarde geschat wordt. Deze conservatievere \(p\)-waarde doet net als bij de Tukey-HSD-test dienst als correctie voor type 1-foutinflatie.
De Games-Howell-test wijkt af van de Tukey-HSD-test (en de Bonferonni-correctie) door een (tamelijk complexe) correctie toe te passen op het aantal vrijheidsgraden.
\[\begin{equation} df' = \frac {\left(\frac{s_i^2}{n_i} + \frac{s_j^2}{n_j} \right)^2} { \frac{\left(\frac{s_i^2}{n_i} + \frac{s_j^2}{n_j} \right)^2} {n_i - 1 + n_j - 1} } \tag{24.28} \end{equation}\]
Deze draak van een formule wordt misschien wat duidelijker met een cijfermatig voorbeeld. Stel dat een gegeven paarsgewijze vergelijking in een Tukey-HSD-test een \(df = 7\) heeft. De onderzoeker vindt dat er altijd uitgegaan moet worden van ongelijke varianties, conform recente statistische inzichten. De variantie van groep A is \(s_A^2 = 2.92\) en van groep B \(s_B^2 = 1.66\). Voor het gemak hebben groep A en B ieder \(n = 4\). De ongelijke varianties maken de vergelijking minder zuiver en de Games-Howell-test verhoogt de \(p\)-waarde bovenop de Tukey-HSD-test door de \(df\) te verkleinen.
\[\begin{equation} df' = \frac {\left(\frac{s_i^2}{n_i} + \frac{s_j^2}{n_j} \right)^2} { \frac{\left(\frac{s_i^2}{n_i} + \frac{s_j^2}{n_j} \right)^2} {(n_i - 1) + (n_j - 1)} } = \frac {\left(\frac{2.92}{4} + \frac{1.66}{4} \right)^2} { \frac{\left(\frac{2.92}{4} + \frac{1.66}{4} \right)^2} {(4 - 1) + (4 - 1)} } = 5.5787 \tag{24.29} \end{equation}\]
Waar de Tukey-HSD-test toetste tegen \(df = 7\), toetst de Games-Howell-test in dit voorbeeld slechts nog tegen een \(df \approx 5.6\). Hoe meer de varianties verschillen, hoe zwaarder de correctie op de \(df\). Een lagere \(df\) heeft een grotere \(p\)-waarde van de toetsstatistiek tot gevolg, waardoor een geobserveerd verschil tussen twee gemiddelden minder snel significant is.
24.6 Kanskapitalisatie
Nu de one-way ANOVA is besproken, gaan we nog even terug naar de reden waarom je beter een one-way ANOVA kunt doen dan verschillende \(t\)-toetsen, en die reden heeft te maken met het begrip kanskapitalisatie. In deze sectie leggen we uit wat dit begrip betekent.
Iedere keer dat er een hypothese wordt getoetst, accepteert men een kans gelijk aan alfa om een significant resultaat te vinden, terwijl dit effect in werkelijkheid niet in de populatie aanwezig is. In de sociale wetenschappen wordt doorgaans een alfa van \(5\%\) gekozen. Deze kans op een fout-positieve bevinding, de kans dat onterecht de nulhypothese wordt verworpen, wordt de type I-fout genoemd. In het geval van een \(t\)-toets wordt een uitspraak daarom gedaan met \(95\%\) betrouwbaarheid \((1 - 0.05)\). Maar wat er als meer \(t\)-toetsen nodig zijn, omdat er meer dan één (paarsgewijze) waarneming wordt vergeleken?
Iedere \(t\)-toets heeft steeds weer een \(5\%\)-kans op een type I-fout. Hypothesetoetsing heeft daarmee veel weg van een dobbelspel waarbij je ‘af’ bent als je een zes gooit. Naarmate het spel vordert en er steeds meer dobbelstenen gegooid zijn, is de kans per worp niet veranderd, maar uiteindelijk wordt de kans dat er minstens eenmaal een zes gegooid wordt bijna \(100\%\).
Zodra er meer dan twee groepen vergeleken worden om een hypothese te toetsen, dan neemt het aantal te toetsen paren snel toe. Als je drie groepen wilt vergelijken, dan zijn er drie \(t\)-toetsen nodig (groep1 versus groep2, groep1 versus groep3, groep2 versus groep3). Bij het vergelijken van vier groepen zijn er al zes paarsgewijze vergelijkingen nodig, en bij vijf groepen zijn dat er al tien. Bij iedere toets loopt de onderzoeker het risico van \(5\%\) op een type I-fout. Hiermee neemt dus ook de kans om op minstens één toets onterecht de nulhypothese te verwerpen bij iedere extra toets toe. Deze toename van type I-fout wordt kanskapitalisatie genoemd.
De hiermee gepaard gaande afname van betrouwbaarheid is exponentieel. De nieuwe betrouwbaarheid is gelijk aan de initiële betrouwbaarheid tot de macht van het aantal toetsen. Bij een alfa van \(5\%\) bijvoorbeeld is de betrouwbaarheid \(95\%\) \((0.95)\). Wanneer er drie toetsen worden gedaan met deze betrouwbaarheid van \(95\%\), is de nieuwe betrouwbaarheid:
\[0.95^3=0.857\]
De type I-fout is dan niet meer \(5\%\), maar:
\[1-0.95^3=0.143\]
Bij het vergelijken van drie groepen in drie \(t\)-toetsen is de type I-fout toegenomen van \(5\%\) tot ruim \(14\%\). Als er vier groepen zouden worden vergeleken waren er zes toetsen nodig, waardoor de nieuwe type I-fout al ruim \(26\%\) zou zijn:
\[1-.95^6 = 0.264\]
En bij vijf vergeleken groepen, waar tien toetsen nodig zijn, is de type I-fout, dus de kans dat er in minstens één toets onterecht de nulhypothese wordt verworpen, al opgelopen tot ruim \(40\%\)!
\[1-0.95^10 = 0.401\]
Een onderzoeker heeft twee manieren om deze toename van type I-fout op te lossen.
In de eerste plaats kan de alfa worden aangescherpt door het kiezen van een post-hoc-correctiefactor. De bekendste hiervan is de Bonferroni-correctie: de alfa wordt dan gedeeld door het aantal getoetste vergelijkingen.
Ten tweede kun je het aantal uit te voeren toetsen verminderen. Dit kan door
- contrasten op te stellen: bedenk a-priori welke vergelijkingen van belang zijn, en welke niet
- omnibustoetsen toe te passen: kies een toets die eerst een algemeen effect toetst, en toets specifieke vergelijkingen pas als de omnibustoets aangeeft dat er ergens verschil is (bijvoorbeeld, one-way ANOVA of factoriële ANOVA.
24.7 Interpretatie van de parameterschattingen van one-way ANOVA
Wanneer we data analyseren met one-way ANOVA, geeft de output naast de hierboven besproken \(F\)-waarde ook zogenaamde parameterschattingen. Om te begrijpen wat die schattingen voorstellen, moeten we een uitstapje maken naar het lineaire model. Het ANOVA-model kan namelijk ook beschouwd worden als een lineair model. De predictorvariabelen zijn dan zogenaamde indicator- of dummyvariabelen die aangeven in welke groep of conditie een persoon zit.
In het volgende voorbeeld wordt dit verder uitgelegd. De eerdergenoemde effectmaat \(R^2\) bij ANOVA wordt ook gebruikt bij een lineair model om aan te geven hoeveel variantie van de afhankelijke variabele door de predictorvariabelen gezamenlijk wordt verklaard. Hier zien we dus al een overeenkomst tussen kwadratensommen en het lineaire model.
24.7.1 Voorbeeld one-way ANOVA
Aan de hand van een voorbeeld wordt one-way ANOVA hieronder geïllustreerd. Stel, we willen weten of we de slaapkwaliteit van mensen kunnen verbeteren. Hierbij willen we onderzoeken of een actieve manier van de avond doorbrengen, bijvoorbeeld door te sporten, de slaapkwaliteit verbetert, of dat juist een rustige voorbereiding, zoals het lezen van een boek, de kwaliteit verbetert.
We laten mensen gedurende twee weken ’s avonds sporten of een boek lezen. Dit zijn de twee experimentele condities. Daarnaast hebben we nog een controleconditie waarin mensen geen instructie krijgen. Iedereen wordt door loting aan een van de drie condities (control, exercise, read) toegewezen.
Na twee weken vragen we aan iedereen die heeft meegedaan aan het onderzoek om op een 7-puntsschaal aan te geven hoe hun slaapkwaliteit de afgelopen weken was, waarbij geldt \(1\) = heel slecht en \(7\) = heel goed. Figuur 24.3 geeft de gerapporteerde slaapkwaliteit van de \(18\) deelnemers weer.
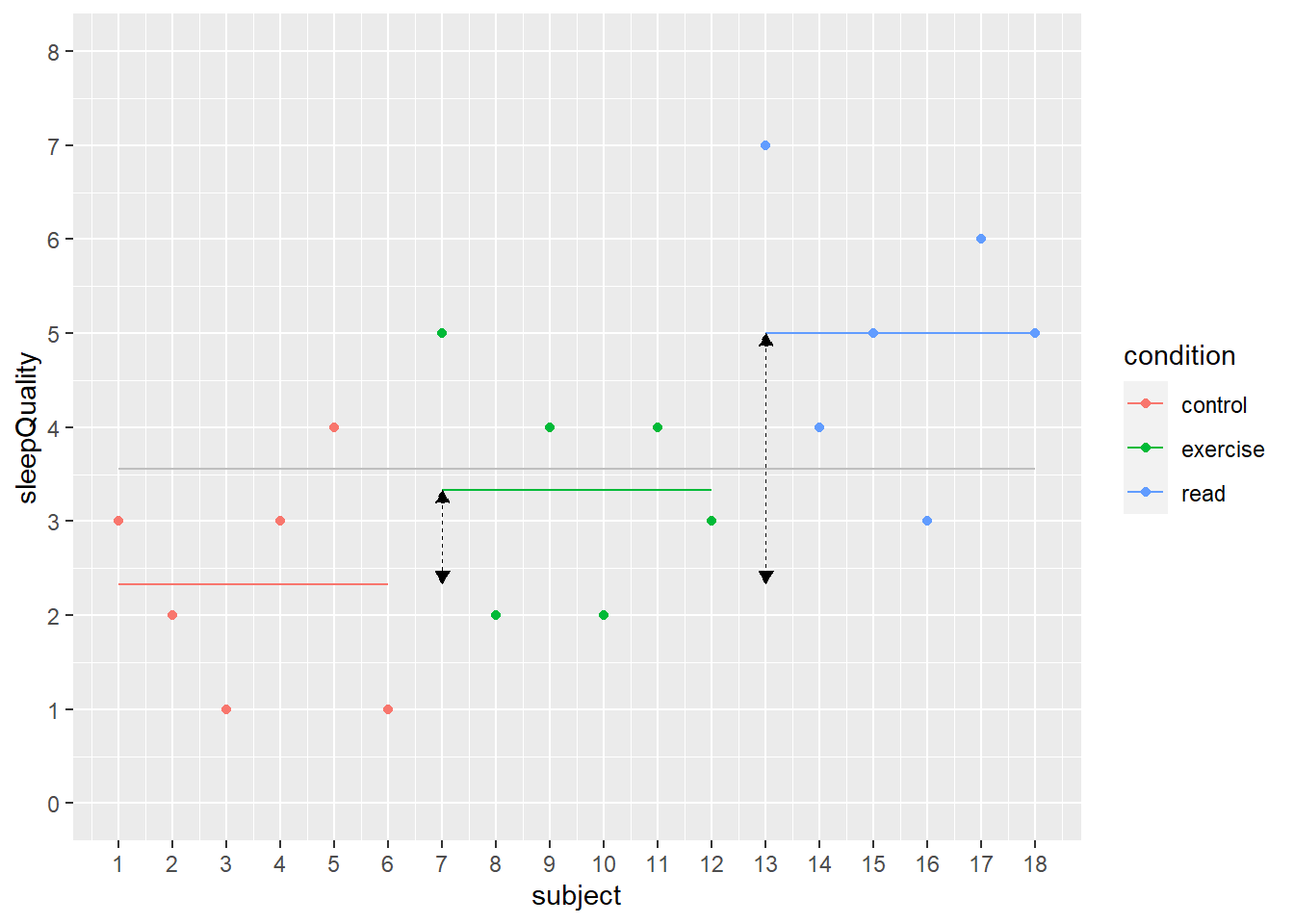
Figuur 24.3: Slaapkwaliteit van \(18\) deelnemers over de drie condities
ANOVA vergelijkt de gemiddelden van de verschillende groepen. Die groepen kunnen in het databestand weergegeven worden door dummyvariabelen. Dat zijn variabelen die de waarden \(0\) of \(1\) hebben, waarbij \(0\) aangeeft dat een persoon niet tot die groep behoort en \(1\) dat deze persoon er wel toebehoort.
In dit voorbeeld zijn er drie groepen (de drie condities van het experiment). Daarmee kunnen we in principe drie dummyvariabelen maken. Het is echter gebruikelijk om één dummyvariabele minder te gebruiken. In dit voorbeeld gebruiken we dus twee dummyvariabelen (exercise, read). Hierdoor bevat het intercept automatisch de informatie van de weggelaten dummygroep (control). Deze groep wordt de referentiegroep genoemd en meestal wordt hiervoor de controlegroep gebruikt.
In het algemeen beschouwen we een van de groepen als referentiegroep waarmee de andere groepen vergeleken worden. De data uit dit voorbeeld, inclusief de dummyvariabelen, zijn in Tabel 24.3 weergegeven. Merk op dat er onder het intercept een kolom met alleen maar \(1\) staat. In het model hoort deze \(1\) bij \(b_0\) en representeert dus een constante waarde die voor iedereen gelijk is.
| subject | sleepQuality | condition | intercept | exercise | read |
|---|---|---|---|---|---|
| 1 | 3 | control | 1 | 0 | 0 |
| 2 | 2 | control | 1 | 0 | 0 |
| 3 | 1 | control | 1 | 0 | 0 |
| 4 | 3 | control | 1 | 0 | 0 |
| 5 | 4 | control | 1 | 0 | 0 |
| 6 | 1 | control | 1 | 0 | 0 |
| 7 | 5 | exercise | 1 | 1 | 0 |
| 8 | 2 | exercise | 1 | 1 | 0 |
| 9 | 4 | exercise | 1 | 1 | 0 |
| 10 | 2 | exercise | 1 | 1 | 0 |
| 11 | 4 | exercise | 1 | 1 | 0 |
| 12 | 3 | exercise | 1 | 1 | 0 |
| 13 | 7 | read | 1 | 0 | 1 |
| 14 | 4 | read | 1 | 0 | 1 |
| 15 | 5 | read | 1 | 0 | 1 |
| 16 | 3 | read | 1 | 0 | 1 |
| 17 | 6 | read | 1 | 0 | 1 |
| 18 | 5 | read | 1 | 0 | 1 |
Het lineaire regressiemodel kan gebruikt worden om ANOVA uit te voeren. Dit model kan in het huidige voorbeeld als volgt worden beschreven.
\[\begin{equation} sleepQuality = b_0 + b_1exercise + b_2read + \epsilon \tag{24.30} \end{equation}\]
De variabele ‘exercise’ is hier een dummyvariabele die de waarde \(1\) heeft bij een persoon die in de conditie ‘exercise’ zit en anders \(0\) is. De variabele ‘read’ is ook een dummyvariabele die de waarde \(1\) heeft bij een persoon die in de conditie ‘read’ zit en anders \(0\) is.
Dit model geeft aan dat iemands’ slaapkwaliteit voorspeld kan worden uit de groep waarin deze persoon zich bevindt. Als iemand bijvoorbeeld in de controlegroep zit, is zowel exercise als read gelijk aan \(0\). Voor deze mensen wordt de slaapkwaliteit dus alleen voorspeld uit het intercept, weergegeven met \(b_0\) in de formule van het regressiemodel. Zoals we zullen zien geeft het regressiemodel aan dat slaapkwaliteit voorspeld kan worden door het groepsgemiddelde van de conditie waarin een persoon valt.
Als we deze data met ANOVA of met het bovengenoemde regressiemodel analyseren, dan geeft deze analyse de onderstaande schattingen voor de parameters \(b_0\), \(b_1\) en \(b_2\). Het intercept is hier \(b_0\), de coëfficiënt behorend bij de dummyvariabele exercise, oftewel behorend bij de conditie ‘sporten’, is \(b_1\) en de coëfficiënt behorend bij de dummyvariabele read, oftewel de conditie ‘boek lezen’, is \(b_2\).
| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | 2.3 | 0.52 | 4.5 | 0.000 |
| conditionexercise | 1.0 | 0.74 | 1.4 | 0.197 |
| conditionread | 2.7 | 0.74 | 3.6 | 0.003 |
De door het model voorspelde waarden kunnen met behulp van de formule en de parameterschattingen worden afgeleid. Laten we eerst kijken naar de voorspelling voor de controlegroep. Voor deze groep zijn de waarden van beide dummyvariabelen exercise en read gelijk aan \(0\). Als we deze waarden invullen in de formule, is de voorspelling als volgt:
\[\begin{equation} sleepQuality(controle) = b_0 + b_1 \times (0) + b_2 \times (0) = \\ 2.33 + 1\times 0 + 2.67\times 0 = 2.33 \tag{24.31} \end{equation}\]
De voorspelde score voor de slaapkwaliteit in de controlegroep is dus \(2.33\). We zien dit getal terug in de eerder getoonde figuur als de rode horizontale lijn. Dit getal is precies het gemiddelde van de scores in de controleconditie.
De voorspelde waarde voor de sportgroep (exercise =\(1\)) wordt als volgt berekend:
\[\begin{equation} sleepQuality(exercise) = b_0 + b_1 \times (1) + b_2 \times (0) = \\ 2.33 + 1\times 1 + 2.67\times 0 =3.33 \tag{24.32} \end{equation}\]
De voorspelde score voor de slaapkwaliteit in de sportgroep is dus \(3.33\). We zien dit getal ook terug in de figuur als de groene horizontale lijn. Dit getal is precies het gemiddelde van de scores in de exercise-conditie. Het verschil tussen de controleconditie en de exercise-conditie wordt in de figuur weergegeven door de gearceerde dubbele pijl tussen de rode en de groene lijn. Dit verschil is \(1\), oftewel de waarde van \(b_1\).
Ten slotte berekenen we de voorspelde waarde voor de leesgroep (read = 1):
\[\begin{equation} sleepQuality(read) = b_0 + b_1 \times (0) + b_2 \times (1) = \\ 2.33 + 1\times 0 + 2.67\times 1 =5 \tag{24.33} \end{equation}\]
De voorspelde score voor de slaapkwaliteit in de leesgroep is \(5\). Ook dit getal zien we terug in de figuur, als de blauwe horizontale lijn. Dit getal is precies het gemiddelde van de scores in de read-conditie. Het verschil tussen de controleconditie en de read-conditie wordt in de figuur weergegeven door de gearceerde dubbele pijl tussen de rode en de blauwe lijn. Dit verschil is \(2.67\), oftewel de waarde van \(b_2\).
De door het model uitgerekende coëfficiënten zijn dus de verschillen ten opzichte van de referentiegroep, in dit voorbeeld ten opzichte van de controlegroep. De interpretatie is daarmee ook duidelijk. Een geschatte coëfficiënt geeft de verbetering van de slaapkwaliteit aan van de desbetreffende conditie ten opzichte van de controlegroep.
| Sum Sq | Df | F value | Pr(>F) | |
|---|---|---|---|---|
| (Intercept) | 33 | 1 | 19.9 | p < .001 |
| condition | 22 | 2 | 6.6 | p = .009 |
| Residuals | 25 | 15 |
In Tabel 24.5 staan de standaardresultaten van een one-way ANOVA weergegeven, zoals de \(F\)-waarden. Verder geeft een ANOVA een effectmaat \(\omega^2\) (hier \(\omega^2\) = 0.38) en Welch’s \(F\).
De \(F\)-waarde met bijbehorende vrijheidsgraden wordt als volgt genoteerd: \(F(\) 2,15) = 6.62, \(p\) = 0.01. Welch’s \(F\), waarbij wordt aangenomen dat de varianties ongelijk zijn, geeft \(F(\) 2,9.95) = 5.79, \(p\) = 0.02.
De conclusie is dat de \(F\)-toets een significant resultaat oplevert en dat de gemiddelden van de drie groepen (condities) van elkaar verschillen. Uit de parameterschattingen blijkt dat ’s avonds sporten weliswaar een verbetering geeft van de slaapkwaliteit, maar dat het lezen van een boek de slaapkwaliteit nog meer verhoogt.