Hoofdstuk 22 Regressie
Auteurs: Gjalt-Jorn Peters, Peter Verboon en Natascha de Hoog; laatste update: 2024-03-08
- inleiding bij regressieanalyse
- het intercept in een regressievergelijking
- de hellingscoëfficiënt in een regressievergelijking
- het structurele model
- proportie verklaarde variantie
- dichotome voorspellers
- centreren en standaardiseren
- aannames van regressie-analyse.
- Onderzoekspracticum inleiding onderzoek (PB0212)
- Onderzoekspracticum cross-sectioneel onderzoek (PB0812)
22.1 Inleiding
In het hoofdstuk Correlaties zijn correlaties en correlatieanalyse uitgebreid besproken. Correlaties drukken het verband tussen twee variabelen kwantitatief uit – onder een aantal aannamen. Vaak willen we echter de mate van samenhang tussen variabelen gebruiken om de waarde op een variabele te voorspellen uit de waarde op een andere variabele. Dan kan bijvoorbeeld de mate van inzet tijdens het Onderzoekspracticum inleiding onderzoek voorspeld worden uit de mate van neiging tot nadenken, de mate van arbeidstevredenheid uit de mate van betrokkenheid, de ernst van depressieve klachten uit de mate van emotiegerichte coping, of het cijfer voor Onderzoekspracticum experimenteel onderzoek uit het cijfer voor Onderzoekspracticum inleiding onderzoek.
Regressieanalyse is die volgende stap. Regressieanalyse is een instrument voor onderzoekers (en studenten) waarmee op basis van de waarde op de ene variabele, een voorspelde waarde op de andere variabele berekend kan worden. Bovendien geeft regressieanalyse een indruk hoe accuraat die voorspelling zal zijn. In dit hoofdstuk starten we met de conceptuele uitleg van regressieanalyse in kleine stapjes. Daarna volgt een voorbeeldcasus.
22.2 De regressielijn
Een regressielijn geeft de beste voorspelling weer van de ene variabele door de andere variabele. Om dit te illustreren kijken we naar \(20\) pinguïns en hun flipperlengte, lichaamsgewicht, snavellengte en snavelhoogte. We zijn geïnteresseerd in het verband tussen die eerste twee (flipperlengte en lichaamsgewicht) en tussen de laatste twee (snavellengte en snavelhoogte). Deze verbanden zijn geïllustreerd in twee scatterplots in Figuur 22.1.
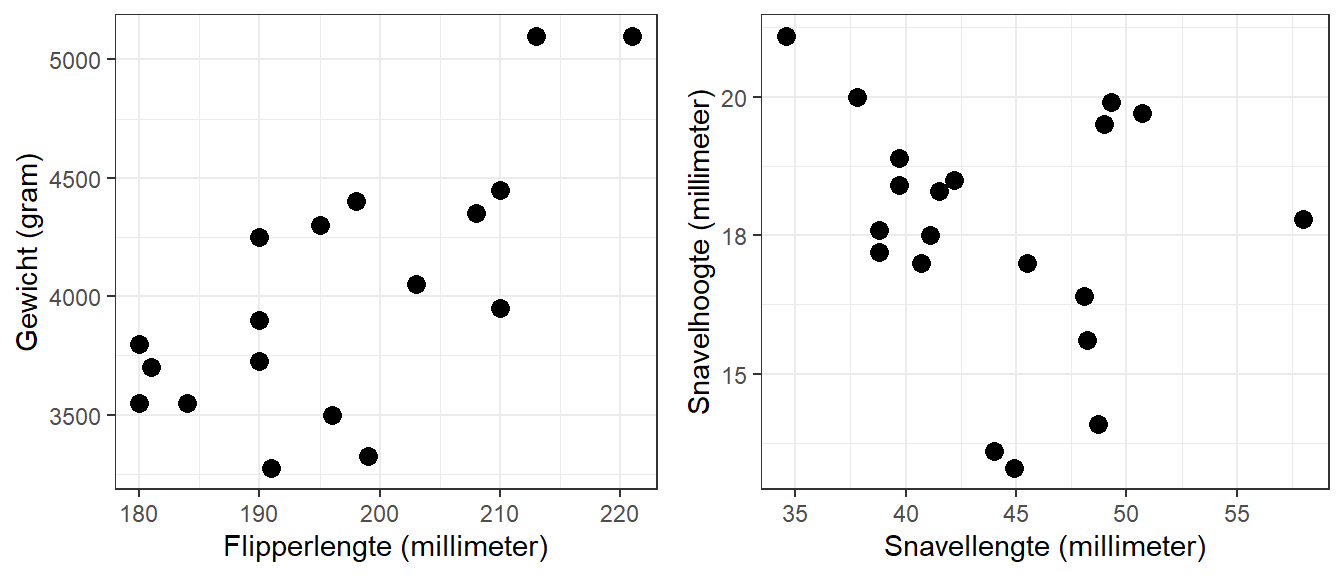
Figuur 22.1: Herhaling van de twee scatterplots voor het verband tussen flipperlengte en gewicht en tussen snavellengte en snavelhoogte
In het hoofdstuk Correlaties hebben we door deze puntenwolken al lijnen getrokken om te illustreren hoe positieve en negatieve verbanden zich manifesteren in zo’n scatterplot. In dit hoofdstuk gaan we berekenen hoe deze lijn loopt. Deze lijn representeert namelijk de beste voorspelling van de ene variabele (meestal de afhankelijke variabele) uit de andere variabele (meestal de onafhankelijke variabele). De beste voorspelling is de lijn die gemiddeld voor alle punten het “dichtst” in de buurt ligt van de daadwerkelijk geobserveerde waarden van de afhankelijke variabele. Figuur 22.2 laat deze zogenaamde regressielijnen zien voor de twee scatterplots.
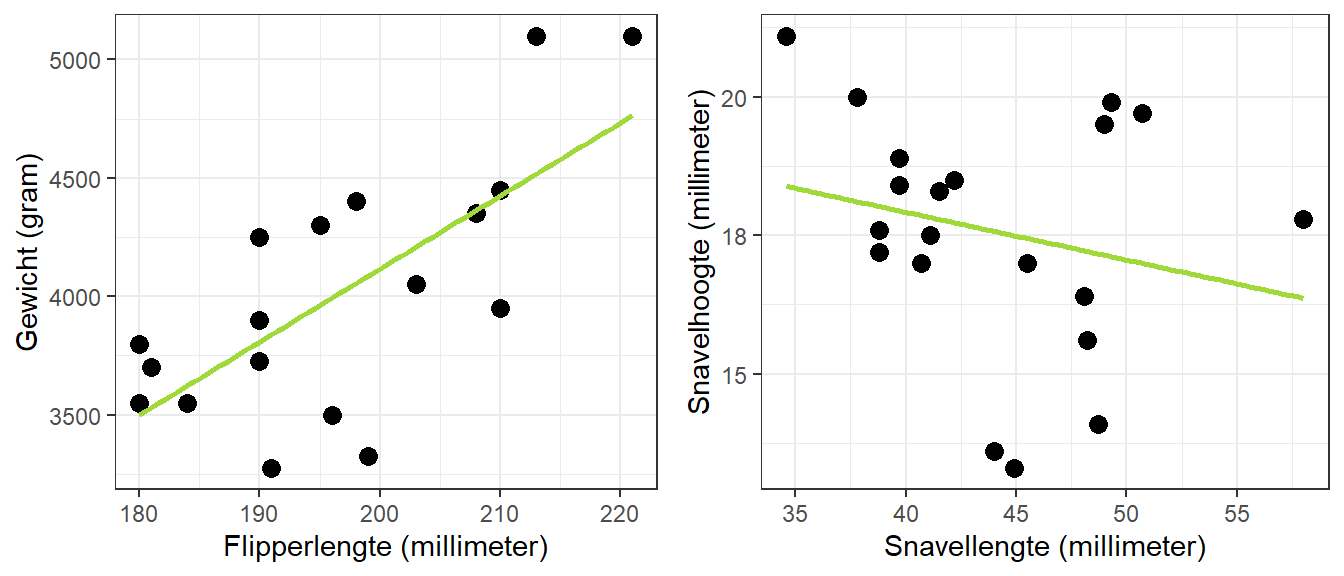
Figuur 22.2: Scatterplots voor het verband tussen flipperlengte en gewicht en tussen snavellengte en snavelhoogte met bijbehorende regressielijnen
Deze regressielijnen zijn het product van regressieanalyse. Bij regressieanalyse gaat het in eerste instantie om twee vragen.
- Hoe vinden we de beste lijn in een willekeurige puntenwolk?
- Hoe goed past deze lijn bij de data?
Met behulp van zo’n regressielijn kunnen we namelijk voorspellingen doen. Als we de score op een predictorvariabele weten, kunnen we de score op een afhankelijke variabele voorspellen. Hoe dichter de punten in de buurt van de lijn liggen, hoe beter die voorspelling zal zijn. In ons voorbeeld loopt de eerste lijn redelijk steil omhoog, terwijl de tweede lijn veel minder steil en omlaag loopt. Figuur 22.3 laat deze regressielijnen zien zonder de stipjes met de geobserveerde waarden.
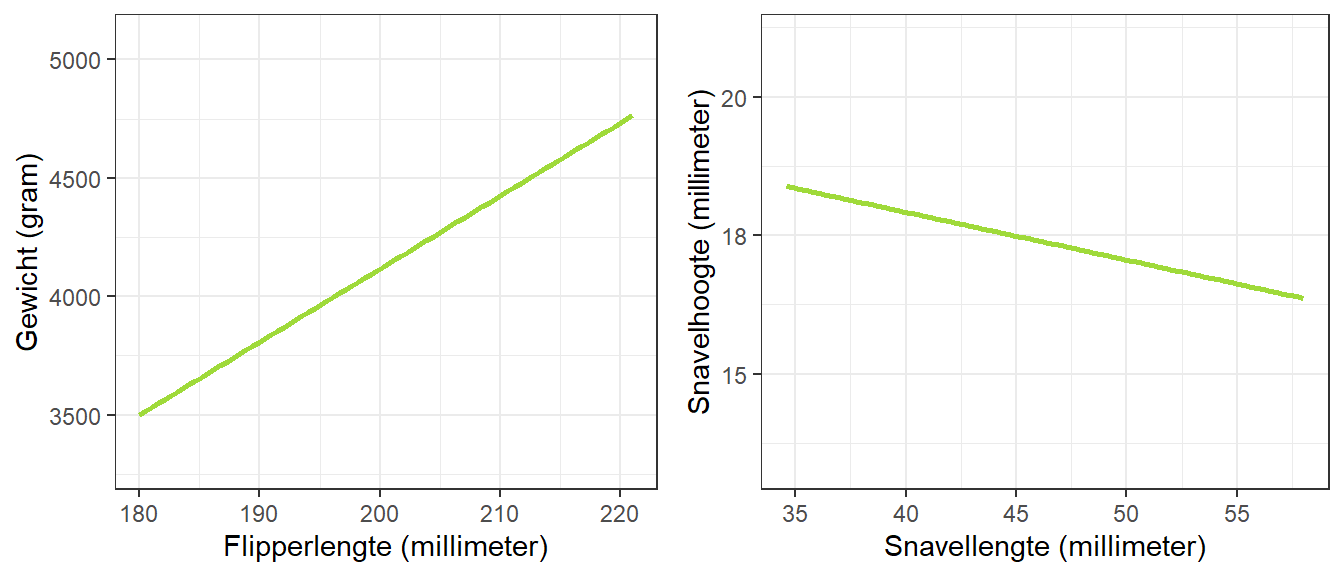
Figuur 22.3: Regressielijnen voor het verband tussen flipperlengte en gewicht en tussen snavellengte en snavelhoogte
Deze plots laten zien wat we op basis van de flipperlengte van een gegeven pinguïn zouden voorspellen voor het lichaamsgewicht van die pinguïn (links) en welke snavelhoogte we zouden voorspellen als we alleen de snavellengte van een pinguïn zouden weten (rechts). Zoals aangegeven loopt de regressielijn links veel steiler dan de rechterregressielijn. Een minder steile lijn betekent een minder sterk verband. Voor de snavelhoogte maakt het dus niet zoveel uit hoe lang de snavel van een pinguïn is. De snavelhoogte hangt dus minder af van de snavellengte, dan dat het lichaamsgewicht afhangt van de flipperlengte.
Maar, deze voorspellingen zijn niet allemaal even goed. Hoe goed de voorspellingen zijn, hangt af van de afstand tussen de geobserveerde waarden en de voorspelde waarden. Hier gaan we in detail naar kijken voor een specifieke pinguïn, Chris. Chris heeft aandoenlijke flippertjes van \(19.6\) cm, weegt \(3.5\) kg en heeft een mooie snavel die \(4.55\) cm lang en \(1.7\) cm hoog is. In Figuur 22.4 zijn Chris’ flipperlengte en snavellengte weergegeven met een zwarte lijn.
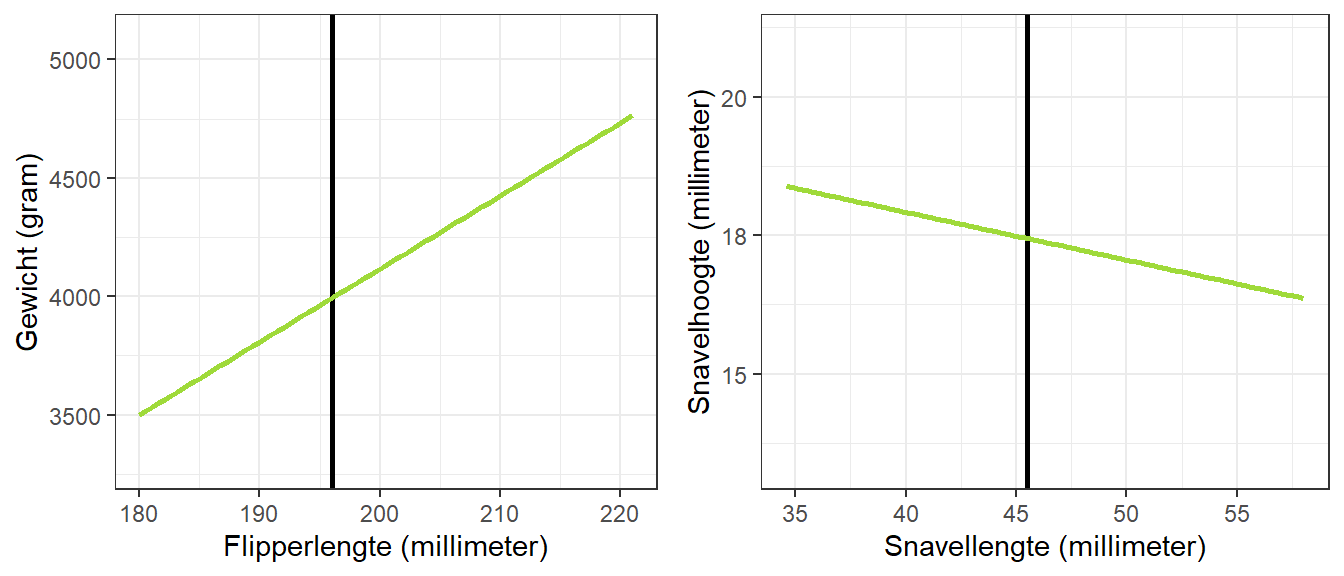
Figuur 22.4: Chris’ flipperlengte en snavellengte (in zwart) gecombineerd met de regressielijnen (in groen)
De lijnen van Chris kruisen de regressielijn. Dat kruispunt is de beste voorspelling die we kunnen produceren voor Chris’ lichaamsgewicht en snavelhoogte op basis van alleen zijn flipperlengte dan wel snavellengte. Door nu een horizontale lijn te trekken waar de regressielijn en de verticale lijn elkaar kruisen, kunnen we zien wat die beste voorspelling is. Dit is weergegeven in Figuur 22.5.
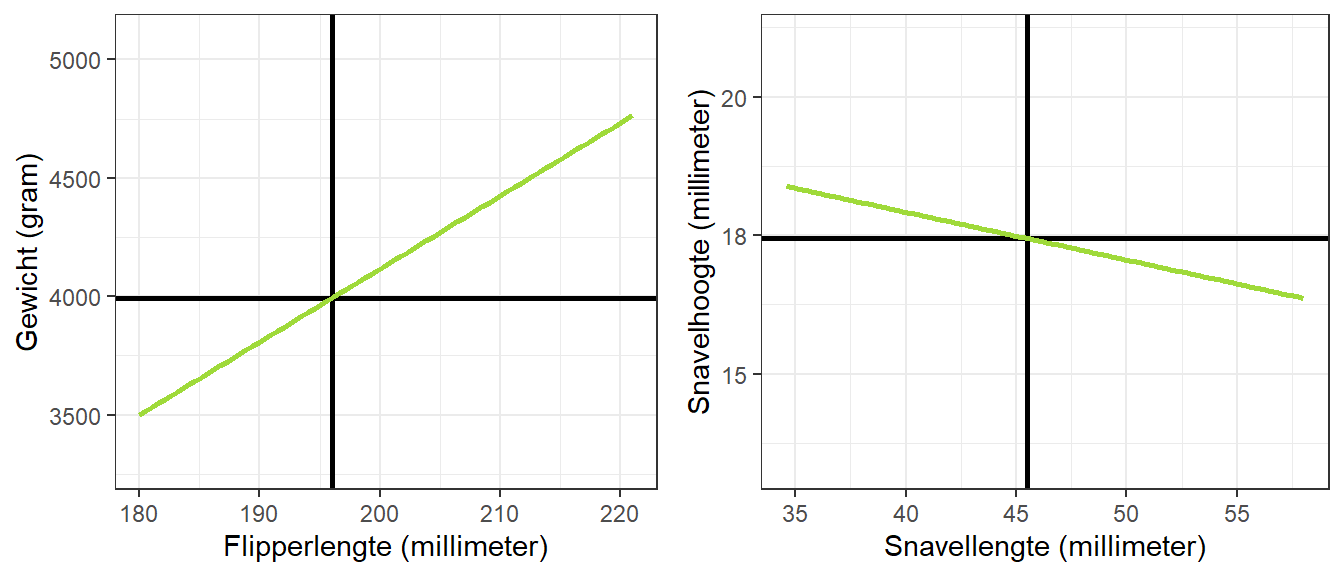
Figuur 22.5: Chris’ voorspelde lichaamsgewicht en snavelhoogte op basis van de regressielijnen
Daar zien we dat de beste voorspelling voor Chris’ gewicht \(3.99\) kg is en de beste voorspelling voor zijn snavelhoogte is \(1.74\) cm. Deze voorspelde waarden zijn niet precies hetzelfde als de geobserveerde waarden: die waren respectievelijk \(3.5\) kg en \(1.7\) cm. Als we de scatterplots weer terugplaatsen in de figuur kunnen we zien waar Chris precies ligt in beide plots. Dit is te zien in Figuur 22.6.
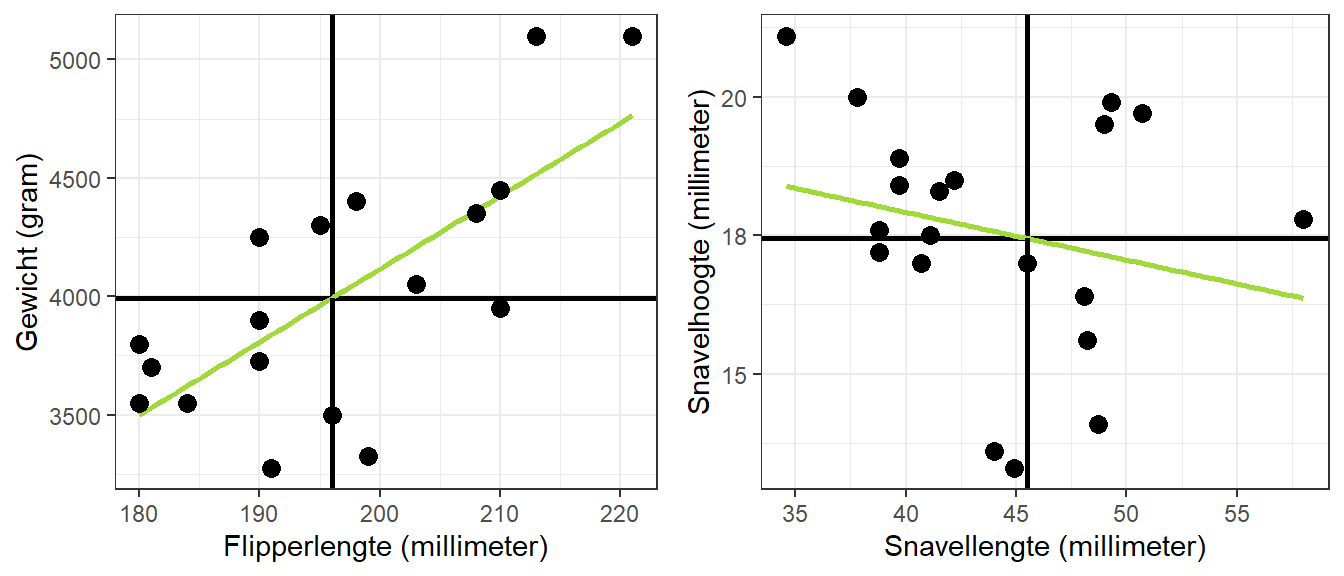
Figuur 22.6: Chris’ voorspelde lichaamsgewicht en snavelhoogte op basis van de regressielijnen en zijn daadwerkelijke lichaamsgewicht en snavelhoogte
We hebben zowel Chris’ lichaamsgewicht als zijn snavelhoogte overschat. Voor andere pinguïns hebben we hun lichaamsgewicht en snavelhoogte juist onderschat. Figuur 22.7 laat deze afwijkingen voor alle pinguïns zien.
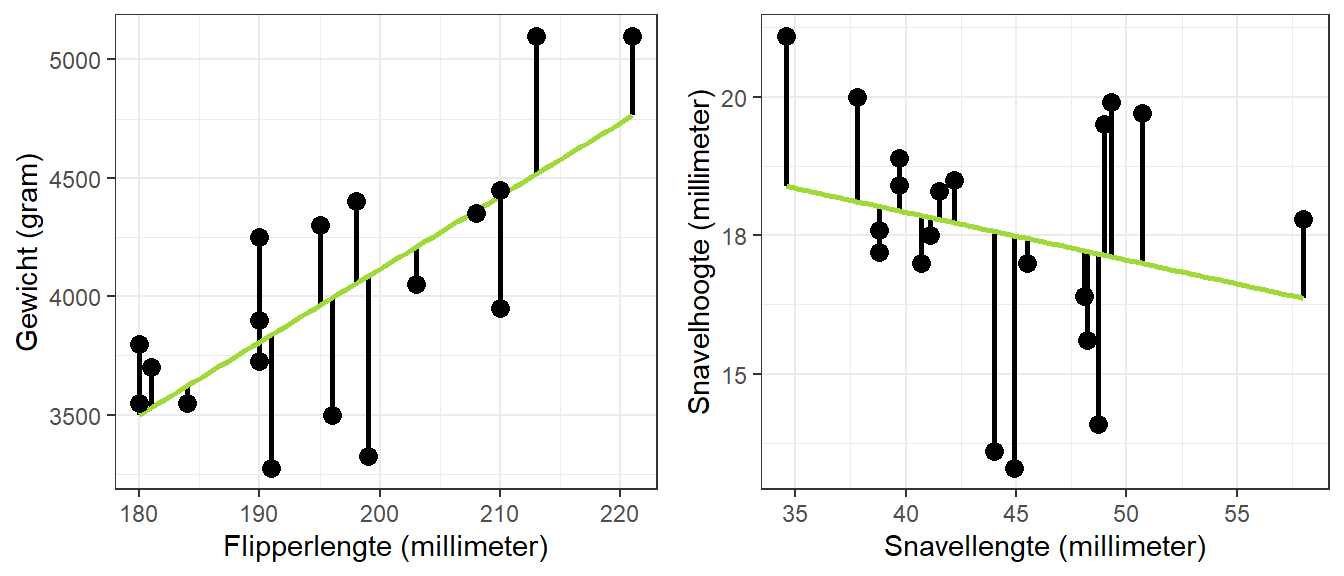
Figuur 22.7: Afwijkingen tussen de geobserveerde en de voorspelde lichaamsgewichten en snavelhoogtes voor alle pinguïns
Deze afwijkingen – of preciezer, het kwadraat van deze afwijkingen – willen we minimaliseren. De lijn moet dus zo lopen dat de afwijking tussen elke geobserveerde \(y\)-score en de correspondeerde voorspelling zo klein mogelijk is. Dat is precies wat regressieanalyse doet: het is een methode om de lijn te vinden waarbij deze (gekwadrateerde) afwijkingen geminimaliseerd worden. De uitkomst van een regressieanalyse zijn twee getallen die de lijn beschrijven. Deze getallen heten de regressiecoëfficiënten en worden aangeduid met b’s of \(\beta\)’s, oftewel bèta’s.
22.3 Het intercept
Het eerste getal uit de regressieanalyse is simpelweg de voorspelling voor iemand die \(0\) scoort op de predictorvariabele, oftewel een waarde van \(0\) op de \(x\)-as. Alle pinguïns uit ons voorbeeld hebben flippers en snavels. We hebben dus geen pinguïn tot onze beschikking die \(0\) scoort op flipperlengte of op snavellengte. We kunnen de regressielijnen die het verband weergeven tussen flipperlengte en lichaamsgewicht enerzijds en snavellengte en snavelhoogte anderzijds wel doortrekken. Dat heet extrapolatie: het berekenen van voorspellingen van een model voor waarden buiten het bereik van de data waarop dat model gebaseerd is. Interpolatie is het gebruik van een model om tussenliggende waarden te berekenen; in ons geval bijvoorbeeld wat de snavelhoogte zou zijn voor een pinguïn met een snavel van \(5,5\) cm.
Als we de regressielijnen doortrekken tot de waarde \(0\) op de \(x\)-as, komen we uit op een voorspeld gewicht van \(-2.05\) kg en een voorspelde snavelhoogte van \(2.14\) cm. Die snavelhoogte lijkt nog wel plausibel: in onze steekproef van twintig pinguïns zit namelijk ook een pinguïn (Daan) met een snavelhoogte van ongeveer \(2,1\) cm. Een lichaamsgewicht van \(-2\) kg is natuurlijk onmogelijk. Dat is niet erg, want we gaan ons regressiemodel alleen gebruiken bij bestaande pinguïns. We zullen in de praktijk dus nooit een flipperlengte van slechts enkele cm tegenkomen en dus ook nooit een pinguïn met een negatief gewicht. Pinguïns kunnen tenslotte niet vliegen.
Deze twee waarden, \(-2051\) gram en \(21\) mm, heten de intercepten van de twee regressiemodellen. Het intercept is de eerste zogenaamde regressiecoëfficiëent in het regressiemodel en wordt aangeduid met \(\beta_0\), \(B_0\) of \(b_0\) (op dat onderscheid komen we later in dit hoofdstuk terug).
22.4 De hellingscoëfficiënt
De tweede regressiecoëfficiënt oftewel, \(\beta_1\), is de helling van de lijn. Deze regressiecoëfficiënt geeft de stijging (of daling) in de variabele op de \(y\)-as aan als de variabele op de \(x\)-as met \(1\) eenheid toeneemt. In ons voorbeeld dus hoeveel gewicht en snavelhoogte toe- of afnemen als flipperlengte dan wel snavellengte met \(1\) mm toenemen. Door in te zoomen op het deel van de grafiek waar de lijn door het intercept loopt, kunnen we deze helling illustreren (zie Figuur 22.8).
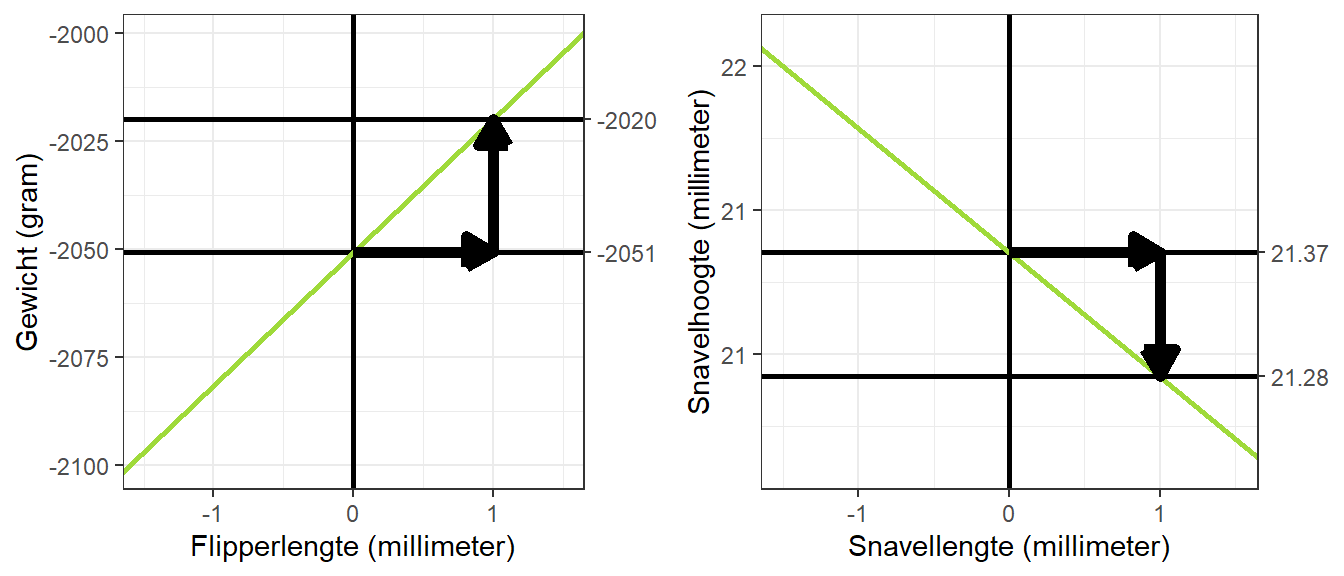
Figuur 22.8: De helling van de regressielijn geïllustreerd
In deze figuur is de groene lijn weer de regressielijn en de overige lijnen representeren het intercept (dat is, het punt op de regressielijn waarbij \(x = 0\)). De horizontale pijl staat voor de verschuiving van \(1\) eenheid op de \(x\)-as vanuit het intercept en de vertikale pijl staat voor de corresponderende verschuiving op de \(y\)-as gegeven het regressiemodel (de groene lijn). De vertikale pijl eindigt dus op het voorspelde lichaamsgewicht van een pinguïn met flippertjes van \(1\) mm lang (in de linker plot) en op de voorspelde snavelhoogte van een pinguïn met een snaveltje van \(1\) mm lang (in de rechter plot). De corresponderende y-waarde wordt weergegeven met de lijn waar de pijl op uitkomt.
Het verschil tussen deze voorspelde waarde op de \(y\)-as en het intercept, is de tweede regressiecoëfficiënt: de hellingscoëfficiënt. Deze is \(30.83\) voor de linkerplot en \(-0.09\) voor de rechterplot.
Nu hebben we per plot beide regressiecoëfficiënten gevonden. Hiermee kunnen we een formule opstellen waarmee we voor elke waarde van de variabele op de x-as kunnen voorspellen welke waarde iemand op de variabele op de y-as zal scoren. Deze formule ziet er als volgt uit uit.
\[ \hat{y} = \beta_0 + \beta_1 x_1 \]
Hierin staat \(\hat{y}\) voor de beste voorspelling van de afhankelijke variabele. In de regressiecontext wordt deze ook wel “het criterium” genoemd. \(\beta_0\) en \(\beta_1\) zijn de regressiecoëfficiënten: de eerste is het intercept en de tweede is de regressiecoëfficiënt voor de helling van de lijn. \(x_1\) is de onafhankelijke variabele, die in de regressiecontext ook wel een covariaat wordt genoemd, omdat hij ‘meevarieert’ met het criterium. De \(\beta\)’s en de onafhankelijke variabele zijn genummerd omdat in regressieanalyse meerdere voorspellers (oftewel onafhankelijke variabelen, oftewel covariaten) tegelijk geanalyseerd kunnen worden. Dat komt nog niet aan bod in dit hoofdstuk, maar wordt behandeld in het hoofdstuk Multipele regressie.
Laten we de formule eens invullen voor beide plots. Voor het verband tussen flipperlengte en gewicht was het intercept \(-2050.61\) en de helling van de lijn was \(30.83\). Dit is in formulevorm weergegeven in vergelijking (22.1).
\[\begin{equation} \hat{y} = \beta_0 + \beta_1 x_1 = -2050.61 + 30.83 x_1 \tag{22.1} \end{equation}\]
Deze formule kunnen we ook in tekst schrijven zoals weergegeven in vergelijking (22.2).
\[\begin{equation} \text{Beste voorspelling lichaamsgewicht} = -2050.61 + 30.83 \times \text{flipperlengte} \tag{22.2} \end{equation}\]
Als de flipperlengte \(0\) is, valt het laatste deel van de formule weg en is de beste voorspelling van het lichaamsgewicht dus gelijk aan het intercept. Naarmate een pinguïn langere flippertjes heeft, stijgt de voorspelling van hun lichaamsgewicht met ongeveer \(30\) gram per mm flipper.
Deze formule kunnen we ook opstellen voor het voorspellen van snavelhoogte uit snavellengte, zoals beschreven in vergelijking (22.3).
\[\begin{equation} \hat{y} = \beta_0 + \beta_1 x_1 = 21.37 + -0.09 x_1 \tag{22.3} \end{equation}\]
In zowel formule (22.1) als formule (22.3) staat \(x_1\)., terwijl in beide formules hiermee een andere variabele wordt aangeduid. Dat komt omdat de nummering van regressiecoëfficiënten en variabelen geldig is binnen elk regressiemodel (zo heet deze formule in een regressieanalyse).
De manier waarop we de regressiecoëfficiënten nu gevonden hebben, is niet hoe statistische software deze berekent. Wij zijn in deze uitleg namelijk met de regressielijn gestart, maar die kan pas getekend worden als beide regressiecoëfficiënten bekend zijn. Statistische software gebruikt schattingsmethoden om de waarden voor \(\beta_0\) en \(\beta_1\) te berekenen.
Er zijn verschillende methoden om regressiecoëfficiënten te schatten, waarvan de twee meest gebruikte ‘ordinary least squares’ en ‘maximum likelihood’ heten. Maar welke methode ook gebruikt wordt, voor regressieanalyse en de berekende regressiecoëfficiënten geldt hetzelfde als voor alle andere getallen die uit een steekproef berekend worden om daarmee iets te zeggen over een populatie: puntschattingen zijn weinig informatief. De betreffende waarde verschilt namelijk van steekproef tot steekproef en kan voor een gegeven steekproef ver afliggen van de corresponderende populatiewaarde (vooral als de standaardfout hoog is, zoals in kleine steekproeven). In plaats daarvan is het belangrijk om te kijken naar betrouwbaarheidsintervallen. Dit wordt verderop in dit hoofdstuk besproken.
22.5 Dichotome voorspellers
Een dichotome voorspeller kan maar twee waarden aannemen. Om een dichotome voorspeller als intervalvariabele mee te nemen in regressieanalyse, moet aan elk van deze twee waarden een getal toegekend worden. Het representeren van de meetwaarden van een categorische variabele met getallen heet dummycoderen. Bij een dichotome variabele krijgen de twee categorieën bijvoorbeeld de waarden \(0\) en \(1\). Deze \(0/1\)-codering heeft als voordeel dat voor de deelnemers in de \(0\)-categorie het regressiemodel een stuk simpeler wordt. Het algemene regressiemodel was namelijk als volgt (22.4).
\[\begin{equation} \hat{y} = \beta_0 + \beta_1 x_1 \tag{22.4} \end{equation}\]
Stel \(x_1\) is een dichotome variabele met dummycodering, waarbij de ene categorie de waarde \(0\) krijgt en de andere categorie de waarde \(1\). Dan kan deze formule dus op de volgende twee manieren worden ingevuld. Voor de eerste categorie (\(0\)) (22.5)
\[\begin{equation} \hat{y} = \beta_0 + \beta_1 0 \tag{22.5} \end{equation}\]
En voor de tweede categorie (\(1\)) (22.6)
\[\begin{equation} \hat{y} = \beta_0 + \beta_1 1 \tag{22.6} \end{equation}\]
De laatste term in het regressiemodel voor de \(0\)-categorie is \(\beta_1 0\), oftewel \(\beta_1\) maal 0. Dit is altijd \(0\), wat de waarde van \(\beta_1\) ook is. Deze term kan dus worden weggelaten. De beste schatting voor de waarde van y voor de deelnemers in de \(0\)-categorie is dus \(\beta_0\), oftewel het intercept.
De laatste term in het regressiemodel voor de \(1\)-categorie kan ook versimpeld worden: \(\beta_1\) maal 1 is altijd \(\beta_1\). De beste schatting voor de waarde van \(y\) voor de deelnemers in de \(1\)-categorie is dus \(\beta_0 + \beta_1\), oftewel het intercept plus de hellingscoëfficiënt. Dit maakt het relatief eenvoudig om de waarden van het intercept en de regressiecoëfficiënt voor de helling te vinden.
Laten we als voorbeeld eens kijken naar het geslacht van pinguïns. In deze dataset is voor elke pinguïn ofwel ‘female’ ofwel ‘male’ geregistreerd. Die kunnen we in dummycodering de waarden \(0\) en \(1\) geven. Onderstaande figuur toont een scatterplot van geslacht als voorspeller van lichaamsgewicht 22.9.
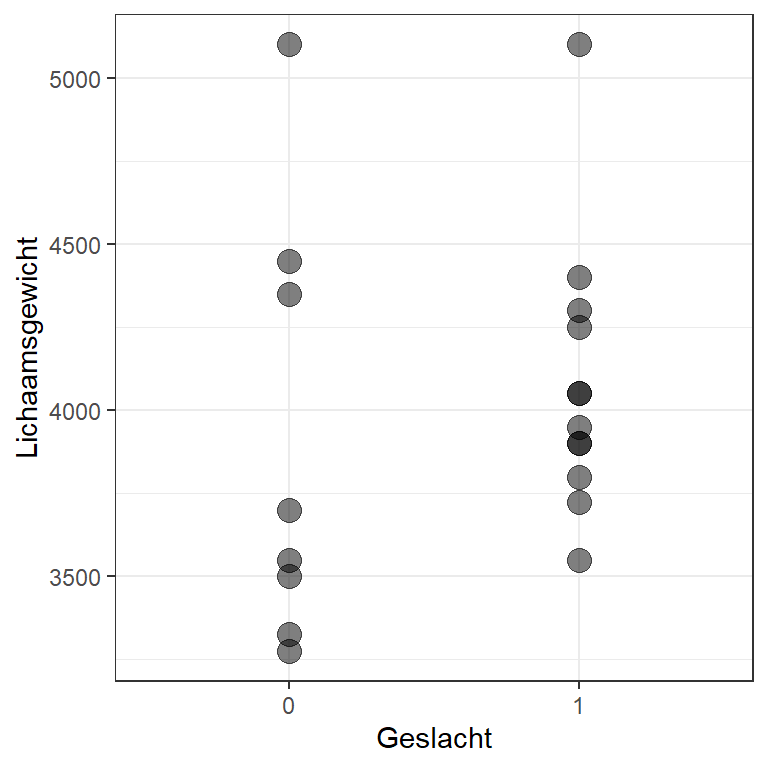
Figuur 22.9: Scatterplot van geslacht als voorspeller van lichaamsgewicht bij 20 pinguïns
Het tekenen van een regressielijn is nu makkelijk. We hebben immers maar twee mogelijke meetwaarden op de x-as: vrouwen en mannen. Onze beste voorspelling voor de waarde van lichaamsgewicht voor vrouwen is het gemiddelde lichaamsgewicht van alle vrouwen en de beste voorspelling voor de waarde van lichaamsgewicht voor mannen is het gemiddelde lichaamsgewicht van alle mannen. Deze gemiddelden en de regressielijn zijn in onderstaande figuur toegevoegd 22.10.
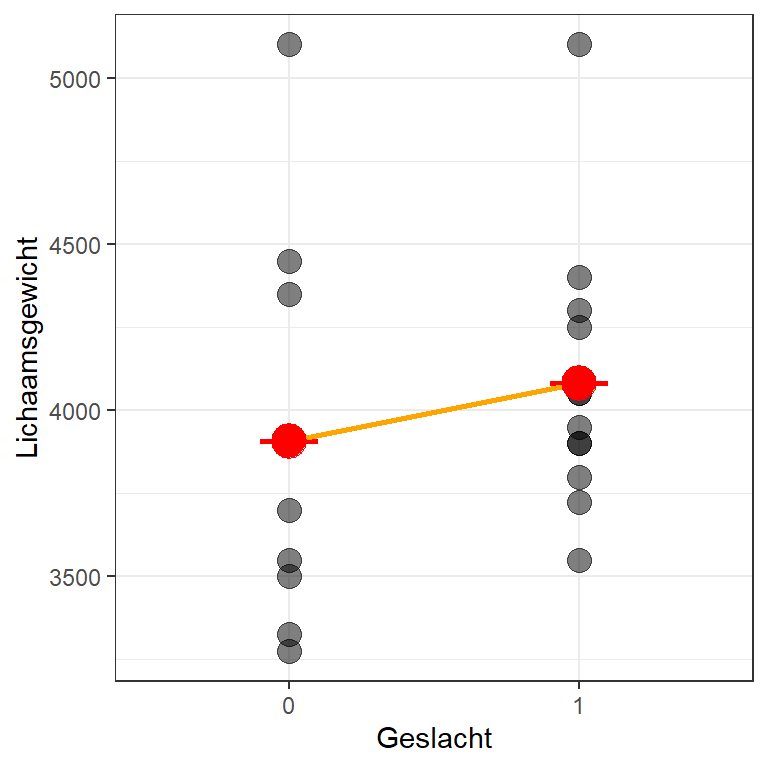
Figuur 22.10: Dezelfde scatterplot met het gemiddelde lichaamsgewicht voor vrouwelijke en mannelijke pinguïns en de regressielijn toegevoegd
Het intercept is in dit geval het gemiddelde lichaamsgewicht van vrouwen (3906.25). De helling is het verschil tussen de twee gemiddelden: dus het gemiddelde van mannen minus het gemiddelde van vrouwen.
\[ 4081.25 - 3906.25 = 175 \]
Bij een dichotome voorspeller is de regressiecoëfficiënt van de helling dus het verschil tussen de gemiddelden in de twee groepen. Deze regressiecoëfficiënt is net als andere regressiecoëfficiënten verdeeld volgens de \(t\)-verdeling met een bijbehorende standaardfout. Als we het verschil tussen de gemiddelden delen door die bijbehorende standaardfout krijgen we dus een \(t\)-waarde en hiermee kunnen we weer een \(p\)-waarde berekenen.
Hoewel het verband tussen een dichotome en een continue variabele dus geanalyseerd kan worden met regressieanalyse, wordt in de praktijk een andere methode gebruikt. Deze andere methode staat centraal in het hoofdstuk Variantieanalyse.
22.6 Het statistische structurele model
Kort samengevat: enkelvoudige regressieanalyse is een uitbreiding van bivariate correlaties naar een voorspellingsmodel. Correlatiecoëfficiënten zijn effectgroottes die gekwadrateerd kunnen worden om een schatting te krijgen van de proportie verklaarde variantie (dat wil zeggen, hoeveel twee variabelen overlappen). Regressieanalyse produceert een regressievergelijking: een model waarmee, gegeven een waarde op de ene variabele, de waarde op een andere variabele voorspeld kan worden.
Anders dan correlatieanalyse is regressieanalyse asymmetrisch: omdat de waarde van de ene variabele voorspeld wordt met de waarde van de andere variabele, maakt de schaalverdeling van elke variabele uit. Daarom is het belangrijk onderscheid te maken tussen de variabele waarmee wordt voorspeld, de predictor of \(x\), en de variabele die wordt voorspeld, het criterium, of \(y\). Als conventie wordt \(y\) bijna altijd een afhankelijke variabele en \(x\) een onafhankelijke variabele genoemd. Het structurele model bij enkelvoudige regressie is weergegeven in Figuur 22.11.

Figuur 22.11: Het structurele model bij enkelvoudige regressieanalyse: links een ellips met label ‘\(x\),’ rechts een ellips met label ‘\(y\)’ en een pijl die van de linker naar de rechter ellips loopt
22.7 De proportie verklaarde variantie
Onderzoekers willen vaak weten hoeveel van de afhankelijke variabele ze nu eigenlijk begrijpen. Een indicator hiervan is hoeveel van de variantie van de afhankelijke variabele verklaard kan worden met een regressiemodel: de ‘proportie verklaarde variantie’ oftewel \(R^2\) (lees: R-kwadraat).
Hoe hoger \(R^2\), hoe meer van de afhankelijke variabele wordt verklaard met de voorspeller(s). Anders gezegd: de \(R^2\) zegt iets over de proportie variantie in \(y\) die door \(x\) verklaard wordt. \(R^2\) kan waarden aannemen van \(0\) tot en met \(1\). Als alle geobserveerde scores, dus de punten in de puntenwolk, exact op een rechte lijn liggen en \(y\) dus perfect uit \(x\) te voorspellen is, zal \(R^2\) gelijk zijn aan \(1\). In dat geval verklaart \(x\) \(100\%\) van de variantie in \(y\)-scores, ofwel \(y\) kan perfect voorspeld worden uit \(x\). Bij enkelvoudige regressie is \(R^2\) gelijk aan het kwadraat van de correlatie tussen predictor en criterium. In het geval van een zwakke correlatie van \(r = .10\) verklaart de predictorvariabele (\(x\)) dus slechts \(1\%\) van de variantie in de criteriumvariabele (\(y\)), want \(.1^2 = .01 = 1\%\).
Naarmate de afstanden tussen de punten en de regressielijn groter worden, of met andere woorden, naarmate de residuen groter worden, wordt de voorspelling slechter. Wanneer de residuen groot zijn, vormt het model een slechte representatie van de werkelijkheid. Wanneer de punten erg verspreid liggen rond de regressielijn, zal \(R^2\) klein zijn en in het geval dat er geen relatie is tussen \(x\) en \(y\), zal \(R^2\) gelijk zijn aan \(0\).
De \(R^2\) is een maat die aangeeft hoe succesvol de afhankelijke variable kan worden voorspeld met de variabelen in het model. Deze maat geeft dus aan hoe goed het model kan voorspellen, maar niet hoe goed het model de werkelijkheid beschrijft. Omgekeerd is het wel waar dat wanneer de \(R^2\) van een model laag is, dit model de werkelijheid niet goed kan beschrijven.
De proportie verklaarde variantie heeft betrekking op de steekproef. Hiermee kun je precies berekenen hoeveel variantie een regressiemodel verklaart in de steekproef. Maar de steekproef is niet interessant en slechts een middel om uitspraken te doen over de populatie, oftewel over de realiteit. Onze steekproef is tot stand gekomen door toeval en steekproeftoeval is dus een verstorende factor.
Bovendien zijn onze metingen gemeten met meetinstrumenten die lijden aan meetfouten en die meetfout is dus ook een verstorende factor. Daarom is het belangrijk om de resulterende ruis in kaart te brengen. Dit kan door betrouwbaarheidsintervallen te berekenen. Daarvoor zijn steekproevenverdelingen nodig.
22.8 Steekproevenverdelingen
Zoals alles dat berekend kan worden uit een steekproef, hebben ook de parameters uit het regressiemodel (\(b_0\) en \(b_1\)) en de proportie verklaarde variantie (\(R^2\)) een steekproevenverdeling.
De steekproevenverdeling van \(b_0\) en \(b_1\) is de zogenaamde \(t\)-verdeling. De \(t\)-verdeling is eigenlijk een variatie op de \(z\)-verdeling met een aanpassing voor kleine steekproeven van bijvoorbeeld \(10\) of \(20\) deelnemers. Zoals eerder uitgelegd zijn dergelijke steekproeven ethisch vaak moeilijk te verantwoorden; vaak is minstens het tienvoudige nodig. Bij zulke grote steekproeven zijn de \(t\)-verdeling en de \(z\)-verdeling praktisch niet te onderscheiden. In Figuur 22.12 staat de \(z\)-verdeling.
Figuur 22.12: De \(z\)-verdeling
In Figuur 22.13 wordt hierbij de \(t\)-verdeling voor steekproeven van \(5\), \(10\), \(15\), \(20\), \(50\), \(100\) en \(200\) deelnemers getekend. De \(t\)-verdeling wordt niet opgesteld voor een gegeven steekproefomvang, maar voor een gegeven aantal vrijheidsgraden (of degrees of freedom, \(Df\)). Bij de berekening van de variantie (‘mean squares’, MS) wordt de variatie (‘sum of squares’, SS) gedeeld door het aantal vrijheidsgraden van die variatie. Op dezelfde manier heeft een regressiecoëfficiënt vrijheidsgraden en die zijn gelijk aan het aantal deelnemers in de steekproef min het totale aantal regressiecoëfficiënten. De t-verdelingen voor \(5\), \(10\), \(15\), \(20\), \(50\), \(100\) en \(200\) deelnemers zijn in dit geval dus de \(t\)-verdelingen voor \(3\), \(8\), \(13\), \(18\), \(48\), \(98\) en \(198\) vrijheidsgraden. We hebben namelijk twee regressiecoëfficiënten: een voor het intercept en een voor de helling.
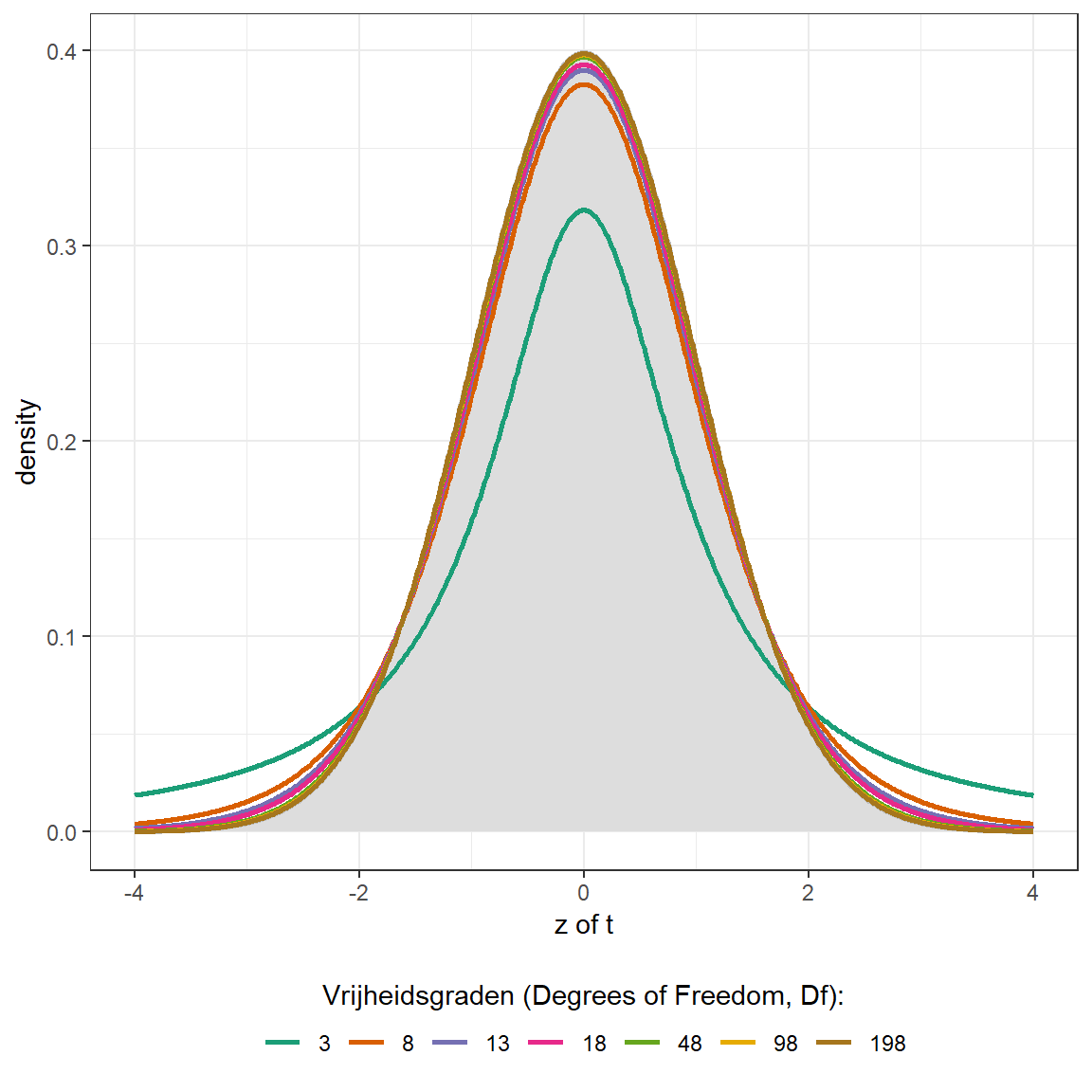
Figuur 22.13: De \(t\)-verdeling voor steekproeven van 5 tot 200 deelnemers en de \(z\)-verdeling
Hier is duidelijk zichtbaar dat de \(t\)-verdeling alleen voor uitzonderlijk kleine steekproeven afwijkt van de normaalverdeling (de \(z\)-verdeling). Naarmate de steekproef groter wordt, gaat de \(t\)-verdeling de normaalverdeling steeds beter benaderen. Omdat dergelijke kleine steekproeven te weinig power hebben om bruikbaar te zijn in onderzoek zijn de \(t\)- en \(z\)-verdeling in de praktijk vaak als equivalent te beschouwen. Toch is het beter om standaard met de \(t\)-verdeling te werken: deze vereist namelijk geen subjectief oordeel over de vraag of een steekproef ‘groot genoeg’ is.
De breedte van de normaalverdeling, oftewel de \(z\)-verdeling, wordt bepaald door de standaarddeviatie. Een \(z\)-waarde van \(1\) correspondeert met een afwijking van \(1\) standaarddeviatie vanuit het midden van de verdeling (voor de \(z\)-verdeling is dat meestal het gemiddelde). Iets vergelijkbaars geldt voor de \(t\)-verdeling: een \(t\)-waarde van \(1\) correspondeert met een afwijking van \(1\) standaardfout vanuit het midden van de verdeling. Een \(t\)-waarde van \(3\) ligt dus \(3\) standaardfouten van het midden van de verdeling af. Om deze \(t\)-verdeling te gebruiken voor een gegeven regressiecoëfficiënt, moeten we de breedte aanpassen aan de standaardfout van die regressiecoëfficiënt.
Hoewel \(R^2\) een eigen steekproevenverdeling heeft, is deze niet makkelijk met de hand uit te rekenen. Omdat \(R^2\) de proportie verklaarde variantie is, wordt vaak de \(F\)-verdeling gebruikt om de \(p\)-waarde te berekenen die uitdrukt hoe groot de kans op de gevonden \(R^2\) is als de voorspeller in de populatie niet samenhangt met de voorspelde variabele. Dit wordt bijvoorbeeld gedaan binnen het kader van nulhypothese-significantietoetsing (NHST; zie hoofdstuk Nulhypothese-significantietoetsing.
22.9 Betrouwbaarheidsintervallen
Anders dan de steekproevenverdeling van Pearson’s \(r\) is de \(t\)-verdeling, de steekproevenverdeling van regressiecoëfficiënten, symmetrisch. Dat betekent dat het betrouwbaarheidsinterval van een regressiecoëfficiënt eenvoudig berekend kan worden als de bijbehorende standaardfout bekend is. De algemene vorm van de formule hiervoor staat in vergelijking (22.7).
\[\begin{equation} \text{betrouwbaarheidsinterval} = \text{steekproefwaarde} \pm \text{breedte-index} \times \text{standaardfout} \tag{22.7} \end{equation}\]
De steekproefwaarde is de puntschatting voor de regressiecoëfficiënt uit onze steekproef. De breedte-index is afkomstig uit de \(t\)-verdeling. Voor een \(95\%\)-betrouwbaarheidsinterval is het de \(t\)-waarde waarvoor geldt dat slechts \(2,5\%\) van de \(t\)-waarden hoger is. Voor de \(z\)-verdeling was dit \(1.96\). Voor de \(t\)-verdeling is dit getal iets hoger en komt steeds dichter in de buurt van die \(1.96\) naarmate de verdeling meer vrijheidsgraden heeft, oftewel naarmate de steekproef groter is. De standaardfout wordt gegeven door statistische software, zoals overigens ook de betrouwbaarheidsintervallen zelf.
Hoe groter de steekproef is, hoe kleiner de standaardfout. Dit betekent dat de betrouwbaarheidsintervallen smaller worden en de regressiecoëfficiënten dus accuraten geschat kunnen worden.
22.10 Nulhypothese-significantietoetsing en \(p\)-waarden
Net als bij de correlatiecoëfficiënt kan ook bij de regressiecoëfficiënt de steekproevenverdeling worden opgesteld voor een populatie-regressiecoëfficiënt van \(0\). Die steekproevenverdeling (een \(t\)-verdeling) bevat dus alle mogelijke regressiecoëfficiënten die gevonden kunnen worden als er in de populatie geen verband tussen de twee variabelen is. Voor de twee regressiecoëfficiënten die hier ter illustratie worden gebruikt, zouden dat de twee steekproevenverdelingen zijn, te zien in 22.14.
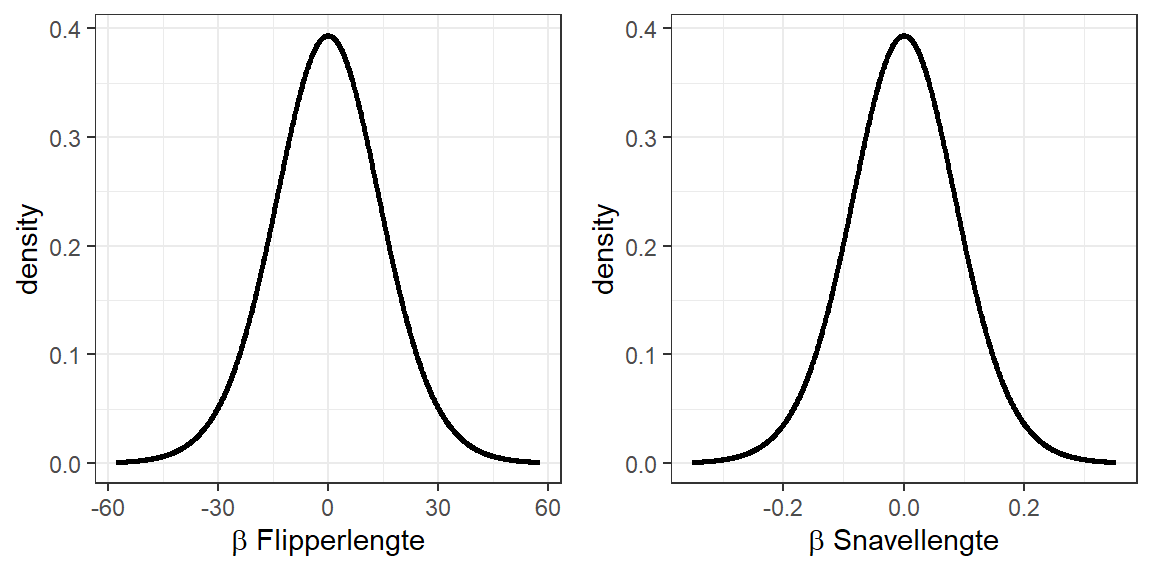
Figuur 22.14: De steekproevenverdelingen, uitgaande van een populatie regressiecoëfficiënt van 0, voor de twee regressiecoëfficiënten voor het voorspellen van pinguïn gewicht uit flipperlengte en snavelhoogte uit snavellengte
Met deze steekproevenverdelingen kan vervolgens de kans worden berekend op elk van deze regressiecoëfficiënten onder de aanname dat deze in de populatie eigenlijk 0 zijn. Hiervoor moeten we eerste weer bepalen welke proportie van deze ‘nulhypothese-steekproevenverdelingen’ hoort bij regressiecoëfficiënten gelijk aan of extremer dan die in onze steekproef 22.15.:
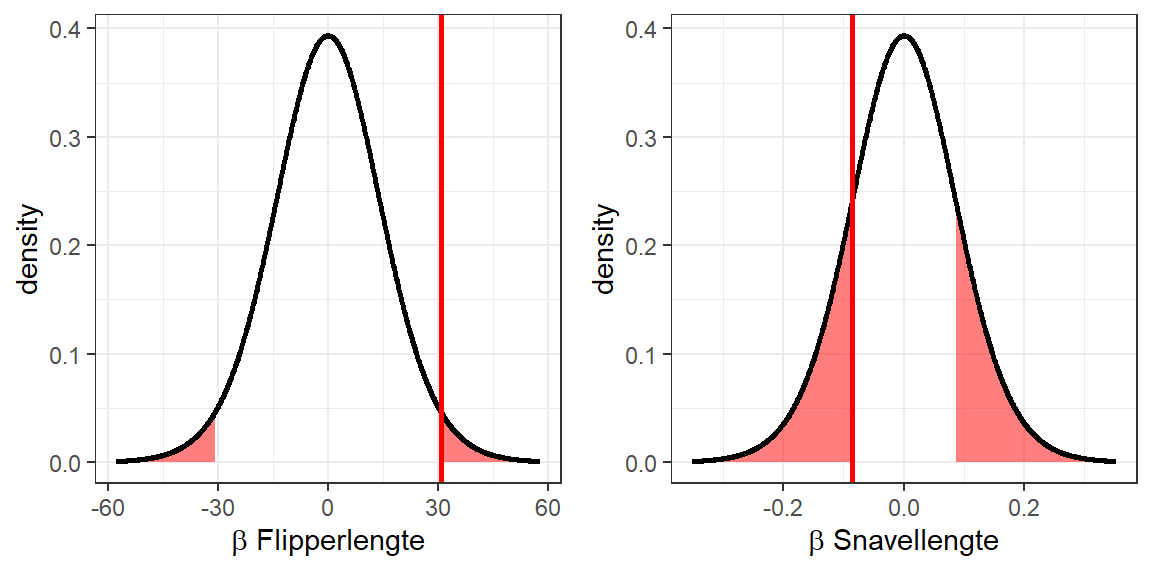
Figuur 22.15: Dezelfde nulhypothese-steekproevenverdelingen, met daarin de gevonden steekproefwaarden voor de coëfficiënten, en de delen van de verdeling die corresponderen met extremere waarden, gemarkeerd.
Deze proporties, oftewel de \(p\)-waarden, zijn \(0.05%\) en \(33.97%\). Binnen het kader van de nulhypothese-significantietoetsing worden \(p\)-waarden lager dan \(5%\) geïnterpreteerd als aanwijzing dat het verband waar die \(p\)-waarde betrekking op heeft, in de populatie ongelijk is aan \(0\). In dit geval zou dus worden geconcludeerd dat de regressiecoëfficiënt die bij linkerfiguur hoort ‘significant’ is (de nulhypothese dat de regressiecoëfficiënt gelijk is aan \(0\) wordt verworpen), en de regressiecoëfficiënt die bij de rechterfiguur hoort niet (de nulhypothese dat de regressiecoëfficiënt gelijk is aan \(0\) wordt niet verworpen).
Er zou dus worden geconcludeerd dat er in de populatie wel een verband bestaat tussen flipperlengte en gewicht, maar dat er geen verband bestaat tussen snavellengte en snavelhoogte.
22.11 Praktijkvoorbeeld: schoolcijfer en IQ
In Figuur 22.16 is de relatie tussen het gemiddelde schoolcijfer en de score op een IQ-test weergegeven voor \(300\) kinderen. Het gemiddelde schoolcijfer is hier de afhankelijke variabele en de score op de IQ-test is de predictor. Een onderzoeksvraag zou kunnen zijn: kunnen we het gemiddelde schoolcijfer van kinderen voorspellen vanuit hun intelligentie (IQ)?
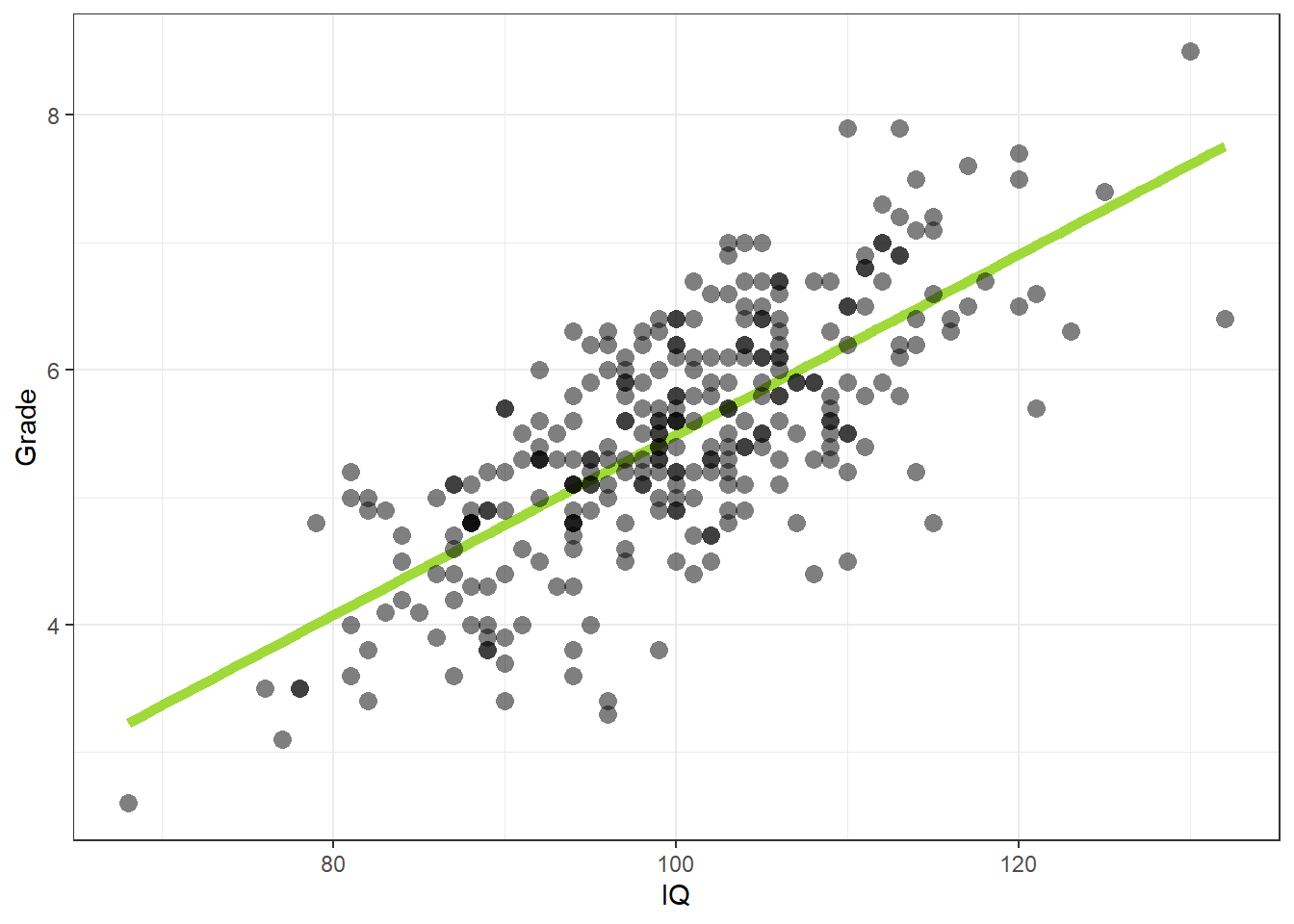
Figuur 22.16: Voorbeeld van een regressielijn door een aantal punten, waarbij elk punt een kind voorstelt met een score op intelligentie (\(x\)-as) en een gemiddeld schoolcijfer (\(y\)-as)
Bij regressieanalyse gaat het in eerste instantie om twee vragen: hoe vinden we de beste lijn in een willekeurige puntenwolk en hoe goed past die lijn bij de data? Met behulp van de regressielijn kunnen we voorspellingen doen: als we de score op een predictorvariabele weten, kunnen we de score op de afhankelijke variabele voorspellen.
Vanuit de wiskunde weten we dat de algemene vergelijking die bij een rechte lijn hoort, de vorm heeft als in vergelijking (22.8).
\[\begin{equation} \hat{y} = b_0 + b_1 x \tag{22.8} \end{equation}\]
In deze vergelijking is \(\hat{y}\) (het dakje staat voor “voorspelde waarde van”) de voorspelling van de afhankelijke variabele (\(y\)). Zoals eerder genoemd is \(b_0\) het zogenaamde intercept van de lijn: het punt waar de lijn de \(y\)-as snijdt wanneer \(x\) gelijk is aan \(0\). \(b_1\) is de hellingscoëfficiënt die aangeeft hoe steil de lijn loopt en \(x\) staat voor de waarde op de \(x\)-as.
Met behulp van de wiskunde kan aangetoond worden dat er altijd maar één enkele lijn is die het beste past in een puntenwolk volgens het eerder genoemde criterium. Hier zal niet verder op ingegaan worden, maar we nemen aan dat er altijd zo’n optimale lijn te berekenen is. De methode die hiervoor gebruikt wordt in dit voorbeeld heet ‘ordinary least squares’ of OLS.
Ook de regressievergelijking heeft de vorm van een lijn. De regressievergelijking representeert een model waarvan getoetst kan worden of deze goed past bij de data. Het model veronderstelt dat er een lineair verband (een rechte lijn) bestaat tussen IQ en schoolcijfer. De lijn in bovenstaande figuur hoort bij vergelijking (22.9).
\[\begin{equation} \text{Voorspeld schoolcijfer} = -1.58 + 0.07 \text{IQ} \tag{22.9} \end{equation}\]
Het voorspelde schoolcijfer is een punt op de lijn. Het doel is om de lijn zodanig te trekken dat de voorspelde schoolcijfers gemiddeld genomen zo dicht mogelijk bij de waargenomen schoolcijfers liggen.
Als eerste lezen we uit de regressievergelijking af dat de waarde voor het intercept \(-1.58\) bedraagt. Het intercept heeft een belangrijke inhoudelijke betekenis. Het is de gemiddelde waarde van \(y\) bij afwezigheid van \(x\) (of beter: wanneer \(x\) de waarde \(0\) heeft). Stel dat we het gemiddelde schoolcijfer (\(y\)) voorspellen op basis van IQ (\(x\)). Het intercept geeft dan het gemiddelde schoolcijfer weer wanneer iemand een IQ van nul (\(0\)) heeft.
De waarde van het intercept is niet zinvol te interpreteren wanneer er geen observaties (kunnen) zijn rond het nulpunt van \(x\). Dat gold voor de pinguïns, maar ook in dit voorbeeld. In Figuur 22.16 zien we dat de eerste observatie begint bij een IQ-waarde van \(68\). In dit voorbeeld is het dus niet zinvol om het intercept te interpreteren omdat een IQ van \(0\) niet bestaat. Dat blijkt bovendien uit de waarde van het intercept (\(-1.58\)) die niet voor kan komen omdat schoolcijfers per definitie niet lager dan \(0\) kunnen zijn. Dat het intercept vaak geen zinvolle interpretatie heeft, is meestal niet erg. Als er wel een zinvolle interpretatie gewenst is, kunnen variabelen worden gecentreerd of gestandaardiseerd. Hier komen we later op terug.
De hellingscoëfficiënt van de lijn wordt in het model de regressiecoëfficiënt genoemd. Een positieve coëfficiënt geeft een positieve relatie tussen de variabelen aan (een stijging van IQ gaat gepaard met een stijging van het voorspelde schoolcijfer). Een negatieve coëfficiënt geeft een negatieve relatie aan (een stijging in IQ gaat gepaard met een daling van het voorspelde schoolcijfer). In dit voorbeeld geeft de regressiecoëfficiënt van \(0.07\) aan dat de waarde van het voorspelde schoolcijfer met \(0.07\) eenheden stijgt wanneer IQ met \(1\) eenheid stijgt. Een stijging van \(10\) IQ punten betekent dus dat het voorspelde schoolcijfer met \(0.7\) stijgt.
Dit betekent overigens niet dat een hoger IQ leidt tot een hoger schoolcijfer. In de praktijk zullen zulke verbanden meestal verklaard worden door andere factoren. In dit geval kan het bijvoorbeeld zo zijn dat kinderen die opgroeien in een gezin met meer ondersteuning daardoor beter presteren op zowel IQ-testen als op schooltoetsen. Een andere verklaring is dat kinderen die beter zijn in het maken van schooltoetsen daardoor meer zelfvertrouwen krijgen waardoor ze beter presteren op IQ-testen. Als beide variabelen zijn gemeten en de voorspeller niet gemanipuleerd is, is regressieanalyse een andere manier om naar correlaties te kijken. En correlatie impliceert geen causatie.
22.12 Een voorbeeld van resultaten
Hieronder staat een voorbeeld van een regressieanalyse. Om deze analyse zelf te reproduceren kan de dataset die in dit hoofdstuk als voorbeeld wordt gebruikt, gedownload worden van https://openmens.nl/data/iq-and-grade.sav. Instructies om het gedownloade bestand te openen, staan op https://rosettastats.com/loading-data. Instructies om een regressieanalyse uit te voeren in statistische software zoals jamovi, R of SPSS, staan op https://rosettastats.com/uni-regression. De tabellen hieronder zijn geproduceerd in R met het rosetta package.
In het databestand (iq-and-grade.sav) staan twee variabelen: IQ en Grade (de variabelenamen en bestandsnaam volgen de richtlijnen van hoofdstuk Data.
22.12.1 De regressieanalyse
22.12.1.1 Regression analysis
Summary
| Formula: | Grade ~ IQ |
| Sample size: | 300 |
| Multiple R-squared: | [.46; .61] (point estimate = 0.53, adjusted = 0.53) |
|
Test for significance: (of full model) |
F[1, 298] = 337.89, p < .001 |
Raw regression coefficients
| 95% conf. int. | estimate | se | t | p | |
|---|---|---|---|---|---|
| (Intercept) | [-2.34; -0.82] | -1.58 | 0.39 | -4.1 | <.001 |
| IQ | [0.06; 0.08] | 0.07 | 0.00 | 18.4 | <.001 |
| a These are unstandardized beta values, called ‘B’ in SPSS. |
Scaled regression coefficients
| 95% conf. int. | estimate | se | t | p | |
|---|---|---|---|---|---|
| (Intercept) | [-0.08; 0.08] | 0.00 | 0.04 | 0 | 1 |
| IQ | [0.65; 0.81] | 0.73 | 0.04 | 18 | <.001 |
| a These are standardized beta values, called ‘Beta’ in SPSS. |
22.12.2 Het model
De \(R^2\) geeft aan hoeveel procent van de variantie in gemiddeld schoolcijfer we kunnen verklaren met IQ. Zoals alles dat wordt berekend uit een steekproef varieert de \(R^2\) van steekproef tot steekproef. Daarom is de waarde van deze puntschatting in deze ene steekproef beperkt relevant. Om iets te concluderen moeten we weten hoe sterk \(R^2\) kan variëren van steekproef tot steekproef en kijken we dus naar het betrouwbaarheidsinterval. Dat loopt hier van \(0.46\) tot \(0.61\). We kunnen dus grofweg de helft van het gemiddelde schoolcijfer voorspellen met het IQ. Vaak wordt ook een ‘adjusted’ \(R^2\) berekend. Hierbij wordt de \(R^2\) naar beneden bijgesteld aan de hand van het aantal voorspellers in het model. De ‘adjusted’ \(R^2\) is alleen relevant als je modellen wilt vergelijken en dat is hier niet aan de orde.
De \(F\)-verdeling wordt gebruikt om te beoordelen hoe groot de kans op deze \(R^2\) is als er in de populatie geen verband is tussen de voorspeller en de afhankelijke variabele. Deze kans is de \(p\)-waarde die bij de berekende \(F\)-waarde hoort. In dit is deze geval kleiner dan \(.001.\) Dat betekent dat als \(R^2\) in de populatie \(0\) is, de kans op de \(R^2\) die wij gevonden hebben kleiner is dan \(0,1\%\).
22.12.3 De regressiecoëfficiënten
In de tabel met coëfficiënten staan het intercept en de hellingscoëfficiënt. Het intercept staat in de meeste programma’s bovenaan en heet ‘Intercept’ of ‘Constant.’ De regel met de hellingscoëfficiënt is herkenbaar omdat deze wordt gelabeld met de betreffende variabelenaam, in ons geval IQ. Ook de hellingscoëfficiënt is berekend uit een steekproef en kan dus variëren van steekproef tot steekproef. We kijken dus weer naar de betrouwbaarheidsintervallen.
Het blijkt dat we de hellingscoëfficiënt voor IQ relatief accuraat kunnen schatten: de kans dat die lager is dan \(0.06\) of hoger dan \(0.08\) is relatief klein (\(0.05\) zou nog wel kunnen, maar \(0.03\) is al heel onwaarschijnlijk). Onze schatting van het intercept is beduidend minder accuraat; dit betrouwbaarheidsinterval loopt van \(-2.34\) tot \(-0.82\). De puntschattingen liggen precies in het midden van deze betrouwbaarheidsintervallen.
Bij elk van de puntschattingen krijgen we ook de bijbehorende standaardfout of ‘standard error’ (\(\text{se}\), de standaarddeviatie van de steekproevenverdeling). De standaardfout geeft informatie over hoe accuraat de schattingen van de regressiecoëfficiënten zijn en wordt gebruikt voor het opstellen van de betrouwbaarheidsintervallen. Door de puntschatting te delen door de standaardfout wordt de \(t\)-waarde verkregen; regressiecoëfficiënten zijn verdeeld volgens de \(t\)-verdeling. De \(t\)-waarde maakt het vervolgens mogelijk om de kans te berekenen dat deze puntschattingen of extremere puntschattingen (dat is, puntschattingen verder van \(0\) af) worden gevonden, als de populatiewaarde \(0\) is (dat is, de \(p\)-waarde). Deze \(p\)-waarde gebruik je voor nulhypothese-significantietoetsing (NHST).
22.12.4 Voorspellingen doen
Aan de hand van de regressievergelijking (zie vergelijking (22.9)) kunnen we nu ook voorspellingen doen. Die voorspellingen worden weergegeven door de regressielijn. Dat wil zeggen, de punten op de regressielijn geven aan welk gemiddeld schoolcijfer voorspeld wordt op basis van de score op de intelligentietest (IQ). Voor iemand met een IQ van bijvoorbeeld \(108\), wordt de voorspelling voor het gemiddelde schoolcijfer: \(-1.58 + 0.07 \cdot 108 = 5.98\) (rekenend met afgeronde regressiecoëfficiënten).
De werkelijke waarde van het gemiddelde schoolcijfer behorende bij de personen in de dataset met een IQ van \(108\) zijn echter \(4.4\), \(5.3\), \(5.9\), \(5.9\) & \(6.7\). Het verschil tussen de voorspelde waarde en deze geobserveerde scores noemen we het residu (of de error). Het residu is voor deze \(5\) mensen dus respectievelijk \(1.58\), \(0.68\), \(0.08\), \(0.08\) & \(-0.72\). Het regressiemodel probeert deze residuen zo klein mogelijk te krijgen.
22.13 De gestandaardiseerde coëfficiënten
In het voorbeeld van het regressiemodel hierboven stonden niet alleen de ruwe regressiecoëfficiënten, maar ook de ‘scaled’ oftewel gestandaardiseerde regressiecoëfficiënten. Deze zijn handig voor de vergelijking van modellen waarbij niet alle predictoren op dezelfde schaal gemeten zijn. Om deze gestandaardiseerde regressiecoëfficiënten te berekenen, voert het statistische programma achter de schermen drie handelingen uit.
- Van elk datapunt wordt het gemiddelde van de betreffende variabele afgetrokken.
- Daarna wordt elk datapunt gedeeld door de standaarddeviatie van de betreffende variabele.
- Daarna wordt de regressieanalyse herhaald met die nieuwe variabelen.
Deze standaardisatie maakt de schaalverdeling van alle variabelen aan elkaar gelijk. Elke gestandaardiseerde variabele heeft een gemiddelde van \(0\) en een standaarddeviatie van \(1\). Een toename van \(1\) betekent een toename van \(1\) standaarddeviatie. In onze steekproef van schoolkinderen is de standaarddeviatie van IQ gelijk aan 9.85 en het gemiddelde is \(99.98\). Om IQ te standaardiseren, wordt dus van het IQ van elke deelnemer in onze dataset \(99.98\) afgetrokken, waarna het resultaat wordt gedeeld door 9.85. Een deelnemer met een IQ van 110 krijgt na de standaardisatie dus een nieuwe waarde van \(1\).
Deze standaardisatie vindt ook plaats voor de afhankelijke variabele. De gestandaardiseerde hellingscoëfficiënt drukt daardoor altijd uit hoeveel standaarddeviaties de afhankelijke variabele verandert (stijgt) als de voorspeller met precies één standaarddeviatie toeneemt. De gestandaardiseerde hellingscoëfficiënten kunnen daardoor tussen modellen vergeleken worden.
Als er twee regressieanalyses zijn uitgevoerd waarbij de voorspellers en afhankelijke variabelen met andere meetinstrumenten gemeten zijn en dus andere schaalverdelingen hebben, dan kunnen we de ruwe regressiecoëfficiënten niet met elkaar vergelijken. De ruwe hellingscoëfficiënt drukt namelijk uit hoeveel meeteenheden de afhankelijke variabele toeneemt als de voorspeller met één meeteenheid toeneemt. De waarde van de ruwe hellingscoëfficiënt is dus afhankelijk van de schaalverdelingen van de voorspeller en de afhankelijke variabele. Een voordeel van ruwe hellingscoëfficiënten is overigens wel dat deze rechtstreeks in het voorspellingsmodel ingevoerd kunnen worden (zie de vorige paragraaf).
Om dit het verschil tussen gestandaardiseerde en ruwe hellingscoëfficiënten verder te illustreren, nemen we als voorbeeld twee modellen met een ruwe hellingscoëfficiënt van \(2,5\) in het ene model en een ruwe hellingscoëfficiënt van \(5\) in het andere model. Dit zou kunnen betekenen dat de afhankelijke variabele in model \(2\) méér toeneemt als de voorspeller stijgt dan in model \(1\). Maar, de getallen (\(2,5\) en \(5\)) zijn afhankelijk van de schaalverdelingen van de voorspellers en de afhankelijke variabelen.
Stel dat de voorspellers in beide modellen en de afhankelijke variabele in model \(1\) gemeten zijn op een schaal van \(1\) tot \(5\), maar dat de afhankelijke variabele in model \(2\) gemeten is op een schaal van \(1\) tot \(20\). Ten opzichte van de gehele schaal van de afhankelijke variabele is \(2,5\) in model \(1\) de helft van de schaal, maar in model \(2\) is \(5\) maar een kwart van de schaal. Een toename van \(2,5\) is hier dus groter dan een toename van \(5\). De corresponderende gestandaardiseerde hellingscoëfficiënten zouden \(.40\) en \(.20\) kunnen zijn. Gestandaardiseerde hellingscoëfficiënten zijn dus gecorrigeerd voor de schaalverdeling en daardoor beter vergelijkbaar tussen modellen.
22.14 Centreren in regressie-analyse
Soms is het handig om een variabele te centreren. Centreren is de eerste stap van standaardisatie: je trekt het gemiddelde van elk datapunt af. Hiermee verandert de schaalverdeling van de variabele dus niet. Het enige gevolg is dat het gemiddelde na het centreren gelijk is aan \(0\).
Als je met een gecentreerde variabele een regressieanalyse doet, is de hellingscoëfficiënt nog hetzelfde, maar het intercept verandert. Het intercept is de waarde van de afhankelijke variabele als de voorspeller de waarde \(0\) heeft. Omdat het gemiddelde van een gecentreerde variabele gelijk is aan \(0\), is de waarde van het intercept gelijk aan de voorspelde waarde van de afhankelijke variabele voor iemand met de gemiddelde score op deze voorspeller.
In ons voorbeeld over schoolcijfers en IQ had het intercept de waarde \(-1.58\). Dit getal heeft geen zinvolle interpretatie omdat de voorspeller IQ nooit de waarde \(0\) kan hebben. Ook is het niet mogelijk om een schoolcijfer van \(-1.58\) te hebben.
Als we nu IQ centreren, wordt het gemiddelde IQ gelijk aan \(0\). Op dat moment wordt het intercept wel interpreteerbaar. Het intercept is dan het voorspelde schoolcijfer voor deelnemers met een gemiddeld IQ (in onze steekproef). Het gemiddelde IQ in onze steekproef was \(99.98\). Door \(99.98\) van elk datapunt af te trekken, centreren we de variabele IQ en wordt het nieuwe gemiddelde 0. Als we de regressieanalyse herhalen, vinden we een intercept van \(b_0 = 5.49\). Dit is dus het schoolcijfer voor iemand met een gemiddeld IQ. De puntschatting voor de hellingscoëfficiënt (\(b_01\)) is hetzelfde gebleven: voor elk IQ-punt meer, is het voorspelde schoolcijfer \(b_1\) hoger.
22.15 Asymmetrie in regressieanalyse
In Figuur 22.11 staat het structurele model van enkelvoudige regressieanalyse weergegeven. De pijl die van de linker ellips met \(x\) naar de rechter ellips met \(y\) loopt drukt de asymmetrische aard van het regressiemodel uit.
Het is belangrijk om goed te onthouden dat deze pijl een statistisch effect uitdrukt. Dat is iets heel anders dan een causaal effect in de methodologische en theoretische betekenis. In de statistiek worden de termen ‘effect’, ‘voorspelling’, en ‘verklaring’ gebruikt om verklaarde variantie uit te drukken, niet om een verondersteld causaal effect te beschrijven. Onthoud dat welke term ook wordt gebruikt, of een verband, effect, voorspelling, of verklaring iets zegt over oorzaak en gevolg ligt besloten in het ontwerp van een studie, en kan nooit worden aangetoond door een statistische analyse alleen.
De asymmetrie zit hem erin dat regressieanalyse aanneemt dat alle error (ruis) in de afhankelijke variabele zit. Regressieanalyse berekent de regressiecoëfficiënten (het intercept en de hellingsregressiecoëfficiënt) zo, dat de afwijkingen tussen de lijn en de punten in de puntenwolk zo klein mogelijk zijn.
In de eerder besproken Figuur 22.16 zie je de regressielijn en datapunten voor de relatie tussen de score op een IQ-test en het gemiddelde schoolcijfer, waarbij het schoolcijfer de afhankelijke variabele is. De afwijkingen tussen de lijn en de punten in de puntenwolk worden in Figuur 22.17 geïllustreerd door de blauwe verticale lijntjes. Deze geven de afstand weer tussen de datapunten en de regressielijn, uitgedrukt op de schaal van schoolcijfer. Alle error wordt hier dus toegekend aan de meting van het schoolcijfer.
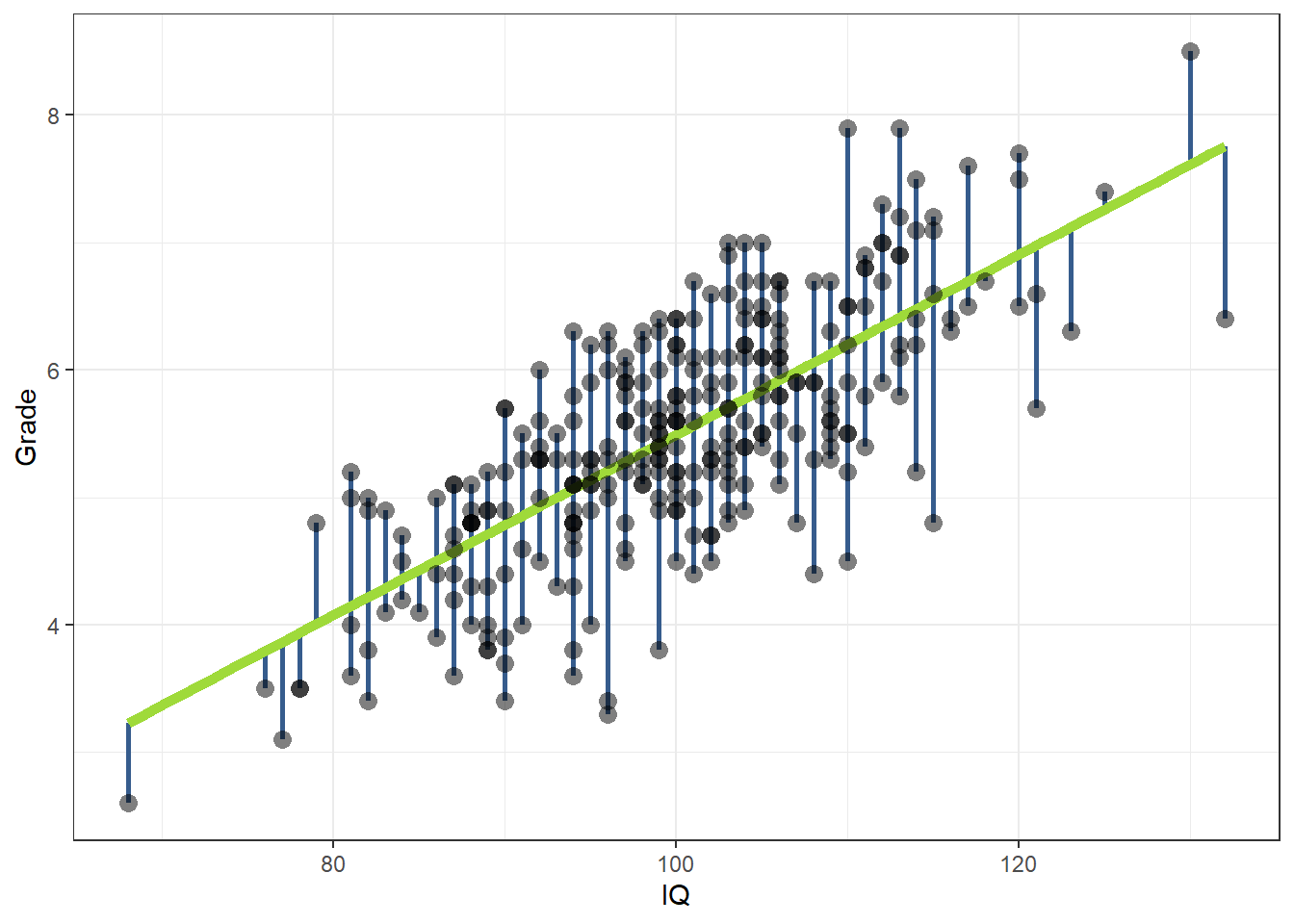
Figuur 22.17: Voorbeeld van een regressielijn door een aantal punten. Elk punt stelt een persoon voor met een score op intelligentie (x-as) en een schoolcijfer (y-as).
Als we deze enkelvoudige regressieanalyse zouden omdraaien, dus het IQ proberen te voorspellen aan de hand van schoolcijfer, dan neemt het model juist aan dat alle ruis in de meting van IQ zit. Dit wordt geïllustreerd in Figuur 22.18. Hier drukken de blauwe verticale lijntjes de afstand van de lijn tot de datapunten uit in termen van IQ.
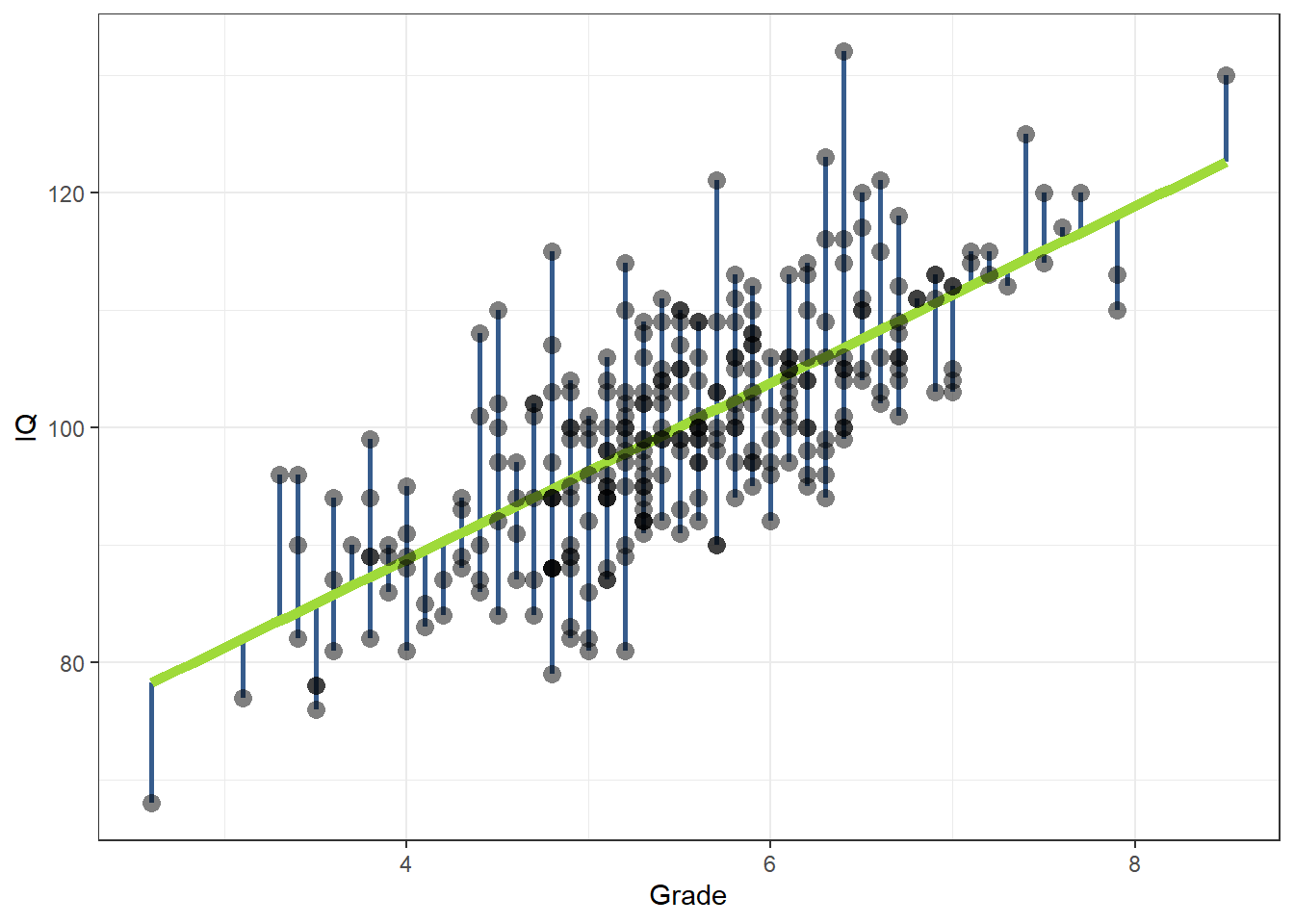
Figuur 22.18: Een omgedraaid regressie-model, waarbij we intelligentie (y-as) voorspellen aan de hand van schoolcijfer (x-as).
Deze lijnen lopen niet hetzelfde. Dit kunnen we zien door deze grafieken naast elkaar te zetten in vierkanten panelen. Daarvoor kantelen we de tweede grafiek negentig graden en stellen we de schaalverdelingen van \(x\) en \(y\) zo in dat ze in beide grafieken gelijk zijn. Het resultaat staat in 22.19.
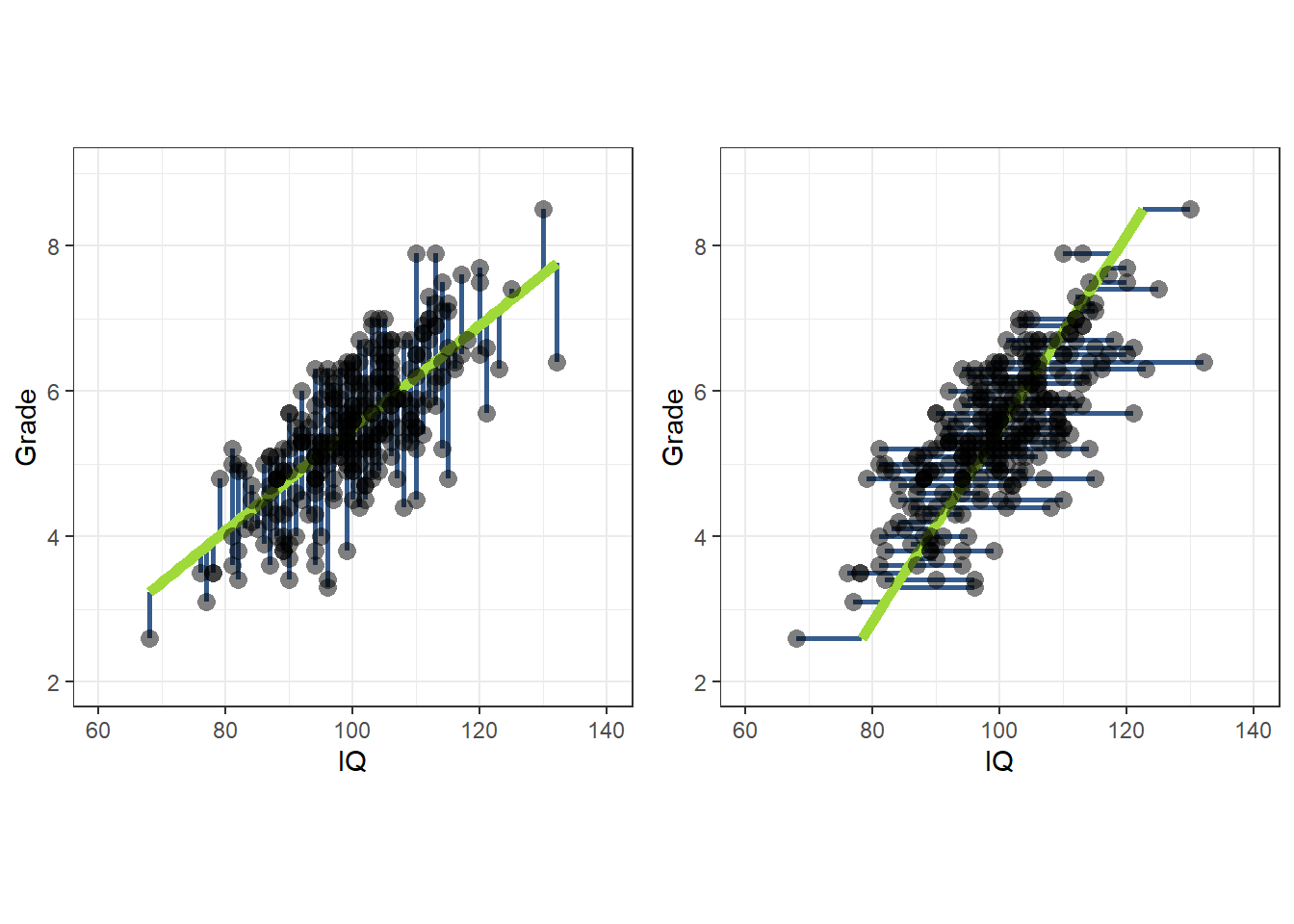
Figuur 22.19: Beide regressie-modellen naast elkaar.
Hoewel de correlatie tussen \(x\) en \(y\) dus altijd hetzelfde is als de correlatie tussen \(y\) en \(x\), zijn de regressiecoëfficiënten anders als je \(y\) voorspelt uit \(x\) dan als je \(x\) voorspelt uit \(y\). Omdat er bij enkelvoudige regressie maar een predictor (onafhankelijke variabele) is, geldt dat de zogenaamde multipele correlatie (\(R\)) gelijk is aan de gewone correlatie tussen de twee variabelen (\(r\)), en dus is de proportie verklaarde variantie (\(R^2\)) gelijk aan \(r^2\). Dus welke variabele je ook specificeert als voorspeller en als criterium (afhankelijke variabele), de proportie verklaarde variantie blijft hetzelfde.
Het is heel belangrijk om je twee dingen te realiseren over deze asymmetrie: de asymmetrie impliceert geen causaliteit en de aanname dat alle meetfout toe te schrijven is aan de afhankelijke variabele is onrealistisch. Als er ook meetfout te verwachten is in de predictoren, dan kunnen beter andere modellen worden gebruikt die deze meetfout in het model opnemen en proberen te schatten. Dit soort modellen worden ‘error-in-variables’ modellen genoemd.
22.15.1 Geen causaliteit
Ten eerste moet je de asymmetrie niet verwarren met de asymmetrie die aanwezig is in structurele modellen over causaliteit. Het structurele model van regressieanalyse lijkt te impliceren dat je het causale verband tussen \(x\) en \(y\) onderzoekt. Dat is niet waar, zoals in de eerste alinea’s van deze paragraaf is uitgelegd. Het gebruik van het asymmetrische regressiemodel maakt het niet opeens mogelijk om conclusies over causaliteit te trekken. Dit vereist altijd een experimenteel studieontwerp.
Er bestaat een belangrijke veel voorkomende uitzondering. Soms hebben onderzoekers op basis van theorie sterke aannames over causale verbanden. In zo’n geval is het niet langer het doel van de onderzoekers om die theorie te onderzoeken. Ze formuleren dan geen hypothesen, maar willen in een specifieke situatie en context in kaart brengen hoe sterk de theoretische verbanden zijn.
Dit gebeurt bijvoorbeeld veel in gedragsveranderingsonderzoek, waarbij vaak uitgegaan wordt van theorieën die menselijk gedrag verklaren met een aantal constructen. Een voorbeeld is de beredeneerd gedrag-benadering (Reasoned Action Approach (RAA)) die is ontwikkeld om beredeneerd gedrag te verklaren en die stelt dat iemands attitude, waargenomen normen en waargenomen gedragscontrole belangrijke voorspellers van gedrag zijn. Onderzoekers nemen deze theorie vaak voor waar aan en willen weten hoe belangrijk die drie constructen zijn bij de verklaring van een gegeven gedrag in een gegeven populatie. In een regressieanalyse wordt dan bijvoorbeeld attitude opgenomen als voorspeller en gedrag als afhankelijke variabele.
Met zo’n regressieanalyse kan niet worden onderzocht óf attitude invloed heeft op gedrag. Maar als onderzoekers bereid zijn om aan te nemen dát attitude invloed heeft op gedrag, kan met die regressieanalyse wel worden onderzocht hoe dat effect zich precies manifesteert in een gegeven populatie en voor een gegeven gedrag.
Laten we als voorbeeld een simpele studie naar dieetgedrag nemen, waarin wordt onderzocht hoe belangrijk attitude en waargenomen normen zijn als voorspellers van calorie-inname. De vraag waarmee attitude wordt gemeten, is ‘Ik vind het beperken van mijn energie-inname…’ met als ankers ‘heel slecht’ en ‘heel goed’, en de vraag naar waargenomen normen luidt ‘De mensen om mij heen vinden dat ik mijn energie-inname…’ met als ankers ‘niet moet beperken’ en ‘moet beperken’, beiden op een zevenpuntsschaal. Het gedrag wordt gemeten door deelnemers in te laten vullen wat ze de vorige dag hebben gegeten en hieruit de calorie-inname in kilocalorieën (kcal) te berekenen.
De onderzoekers kunnen dan een regressiemodel uitvoeren waarin kilocalorieën worden voorspeld door attitude, en een regressiemodel waarin kilocalorieën worden voorspeld door waargenomen normen. Hieruit blijkt bijvoorbeeld dat een toename van \(1\) punt in attitude leidt tot een afname van de calorie-inname met [\(32; 74\)] kcal op basis van een \(95\%\)-betrouwbaarheidsinterval, terwijl een toename van \(1\) punt in waargenomen normen leidt tot een afname van de calorie-inname van [\(162; 228\)] kcal.
De onderzoekers kunnen op basis van de verzamelde data en de uitgevoerde analyses niet concluderen dat ze evidentie hebben gevonden dat attitude en waargenomen normen invloed hebben op gedrag. Dat is een causale uitspraak en die kan alleen worden onderzocht met een experiment.
De onderzoekers kunnen wel concluderen dat áls ervan uit wordt gegaan dat de gebruikte theorie, de beredeneerd gedrag-benadering, klopt, dat in dat geval de rol van waargenomen normen groter lijkt dan die van attitude. Dus als bij het ontwikkelen van een gedragsveranderingscampagne voor die specifieke populatie en context, lijkt het dus goed om de campagne te richten op normen en niet op attitude. Dit soort onderzoek is zeer waardevol, ook al kunnen er geen conclusies over causaliteit worden getrokken.
22.15.2 Onrealistische aanname
Welbeschouwd is het bij onderzoek met mensen bijna nooit realistisch dat de meetfout alleen in de afhankelijke variabele zit. In de meeste studies binnen de psychologie, onderwijswetenschappen of managementwetenschappen worden alle variabelen in de studie gemeten met meetinstrumenten. Alle variabelen hebben dus meetfout. Er zijn bijna geen situaties denkbaar waarin bij het bouwen van een model de meetfout redelijkerwijs volledig toegeschreven kan worden aan de afhankelijke variabele.
Er is een andere analysetechniek die wel meetfout in alle variabelen modelleert. Deze techniek heet ‘structural equation modeling’ (SEM) en combineert in dezelfde analyse factoranalyse en regressieanalyse. SEM is complexer dan regressieanalyse en wordt verder niet behandeld in het curriculum.
22.16 Aannames van regressie-analyse
In een enkelvoudige regressieanalyse worden vijf aannames gemaakt. De eerste vier van deze aannames zijn ‘harde’ aannames: als deze worden geschonden, is het regressiemodel het verkeerde model. Naarmate de harde aannames meer worden geschonden, neemt de zuiverheid van de schattingen van de regressiecoëfficiënten en de proportie verklaarde variantie af.
Schending van de vijfde aanname, een ‘zachte’ aanname, maakt het model minder efficiënt. Naarmate de zachte aanname meer wordt geschonden, neemt de accuraatheid van de schattingen van de regressiecoëfficiënten en de proportie verklaarde variantie af. Er zijn dan meer datapunten nodig, maar er wordt geen ‘bias’ geïntroduceerd. De vijf aannames worden hieronder toegelicht.
Continu meetniveau. In een regressieanalyse wordt aangenomen dat beide variabelen een continu meetniveau hebben (dus interval of ratio). Het meetniveau van de variabelen ken je als het goed is al voordat je data gaat verzamelen. Als je er over twijfelt, bijvoorbeeld als er een nieuw meetinstrument wordt gebruikt waarbij het meetniveau nog niet bekend is, zijn er technieken om te kijken welk meetniveau waarschijnlijker is, maar die vallen buiten het curriculum.
Lineariteit. Regressieanalyse veronderstelt dat het verband tussen de twee variabelen lineair is. Dat betekent dat voor elke waarde van de ene variabele de toe- of afname van de andere variabele hetzelfde moet zijn. Als de toe- of afname in de afhankelijke variabele hoger of lager is wanneer de voorspeller een lage of een hoge waarde heeft, dan kan enkelvoudige lineaire regressieanalyse het verband niet goed modeleren.
Onafhankelijkheid. Regressieanalyse neemt aan dat alle observaties onafhankelijk zijn. Het gaat hier niet om de observaties van de onafhankelijke en de afhankelijke variabele. Deze worden namelijk bij dezelfde onderzoekseenheid gemeten. Verondersteld wordt dat de onderzoekseenheden onafhankelijk zijn.Als er bijvoorbeeld data worden verzameld bij leerlingen uit meerdere klassen of bij deelnemers van verschillende afdelingen binnen een organisatie, dan kan regressieanalyse niet worden gebruikt. Dat komt omdat de onderzoekseenheden (deelnemers) van dezelfde klas of afdeling meer met elkaar gemeen hebben dan met onderzoekseenheden van andere klassen of afdelingen. Zij zijn dus niet zomaar uitwisselbaar: de observaties van de leerlingen uit dezelfde klas zijn niet onafhankelijk.
Normaliteit. Regressieanalyse neemt ook aan dat voor elke waarde van de voorspeller, de afhankelijke variabele normaal verdeeld is, oftewel dat de ruis (de error) normaal verdeeld is. Dit is nodig vanwege het algoritme dat in regressieanalyse wordt gebruikt om de best passende lijn te bepalen (en dus de regressiecoëfficiënten). De definitie van ‘best passende’ lijn is de lijn waarbij de residuen zo klein mogelijk zijn (dit heet ook wel ‘ordinary least squares’ of ‘ols’). Als de error in de afhankelijke variabele niet gemiddeld nul is, klopt dat algoritme niet.
Overigens gaat het er formeel om dat de error gemiddeld \(0\) is. Als de error normaal verdeeld is, is de error altijd gemiddeld \(0\). Technisch gezien zijn andere symmetrische verdelingen met gemiddelde \(0\) ook goed. Meestal wordt deze voorwaarde geïnspecteerd door de residuen van het regressiemodel op te slaan en in een histogram te plaatsen. Hiermee kan snel de verdelingsvorm worden geïnspecteerd.
- Homoscedasticiteit. Dit betekent homogeniteit (gelijkheid) van varianties. Deze aanname houdt in dat voor elke waarde van de onafhankelijke variabele, de variantie in de afhankelijke variabele gelijk is. Als deze zachte aanname wordt geschonden zijn de regressiecoëfficiënten geen efficiënte schatters meer.
Er zijn twee manieren om te bepalen of er sprake is van homoscedasticiteit. Ten eerste kun je de scatterplot bestuderen. Als de punten niet overal even ver van de regressielijn af liggen, maar bijvoorbeeld in een trechtervorm, dan wordt de homoscedasticiteit geschonden. Ten tweede zijn er toetsen om homoscedasticiteit te bepalen. Als je de voorspeller in vier (of drie of vijf) groepen verdeelt, kun je Levene’s test gebruiken om te inspecteren of de varianties in die vier groepen gelijk zijn.
22.17 Synoniemen
Omdat er bij regressieanalyse veel verschillende termen zijn voor dezelfde dingen, volgt hier een lijstje met synoniemen.
- onafhankelijke variabele = voorspeller = predictor = covariaat
- afhankelijke variabele = criterium
- proportie verklaarde variantie = \(R^2\)
- intercept = de eerste regressiecoëfficiënt; maar let op:
- regressiecoëfficiënt = de hellingscoëfficiënt, omdat er bij enkelvoudige regressie maar twee regressiecoëfficiënten zijn, en het intercept meestal niet zo interessant is.
In de statistiek is de conventie om het Griekse karakter te gebruiken als het over de populatie gaat en het Latijnse karakter als het over een steekproef gaat. Maar bij regressieanalyse wordt het Griekse karakter (\(\beta\)) ook gebruikt om naar de gestandaardiseerde regressiecoëfficiënten in de steekproef te verwijzen. Voor de ruwe regressiecoëfficiënten wordt het Latijnse karakter gebruikt (‘b’ of ‘B’).Dit kan verwarrend zijn, dus is het verstandig om altijd expliciet te benoemen of het symbool (\(\beta\)) staat voor de populatiewaarde van de ongestandaardiseerde regressiecoëfficiënt of voor de steekproefwaarde van de gestandaardiseerde regressiecoëfficiënt.
22.18 Met de hand regressiecoëfficiënten berekenen
Bij enkelvoudige regressie kunnen regressiecoëfficiënten ook met de hand worden berekend. De regressiecoëfficiënt van de helling kan worden berekend met de formule in vergelijking (22.10).
\[\begin{equation} \hat{\beta}_{1_{\text{y voorspellen uit x}}} = r_{xy} \frac{sd_y}{sd_x} \tag{22.10} \end{equation}\]
Als de hellingscoëfficiënt eenmaal is berekend, kan deze worden gebruikt om het intercept te berekenen. De formule hiervoor staat in vergelijking (22.11).
\[\begin{equation} \hat{\beta_0} = \overline{y} - \beta_1 \overline{x_1} \tag{22.11} \end{equation}\]
Deze formule laat duidelijk zien waarom het intercept altijd \(0\) is als beide variabelen zijn gestandaardiseerd. In dat geval zijn de gemiddelden van beide variabelen namelijk \(0\). Als de voorspeller (\(x_1\)) \(0\) is, is de beste voorspelling van de afhankelijke variabele (\(\hat{y}\)) dus ook \(0\), en daarmee dus ook het intercept. Als er niets bekend is, maar toch een voorspelling moet worden gedaan voor de waarde van de afhankelijke variabele, dan is het gemiddelde de beste keuze. Daar liggen alle datapunten tenslotte omheen.
Overigens laten deze formules ook gelijk de kern van de hierboven besproken asymmetrie zien. Dit wordt duidelijk als we de formule voor de hellingscoëfficiënt omdraaien zodat we x kunnen voorspellen uit y, zoals weergegeven in vergelijking (22.12).
\[\begin{equation} \hat{\beta}_{1_{\text{x voorspellen uit y}}} = r_{xy} \frac{sd_x}{sd_y} \tag{22.12} \end{equation}\]
In deze formule verwisselen de standaarddeviaties van plek, waardoor de hellingscoëfficiënten veranderen. Hoewel de correlatie van x met y dus gelijk is aan de correlatie van y met x, is de hellingscoëfficiënt van x als voorspeller van y anders dan de hellingscoëfficiënt van y als voorspeller van x.